Archive
Python: Pandas Lesson 5
Learning : Pandas Lesson 5
Subject: Columns rename and missing data.
We are still in the same track looking after commands that help us in managing and formatting the dataframe. In most cases, we will have a data file from the net, or from a source that may not consider formatting or standardization as his/their concern, or we may find a lots of missing data in the file. In this post we will go through some lines that will make the file in better shape.
Columns, First thing we will look at is the head of the data table. So First, check your data columns with this code:
print(‘\n\n Current columns of the data.\n’,df3.columns)
Now we have the a list of the columns in our datafile, and we can change any of them just to give a more clear meaning or any other purpose. I found that using rename method and passing new columns names as dictionary is better because we can rename without order also not stick to rename them all.
df.rename(columns={‘animal’:’Animal-Kind’,’id’:’ID’,’cage_no’:’InCage’}, inplace=True)
print(‘\n\n Table with new renaming columns .\n’,df3)
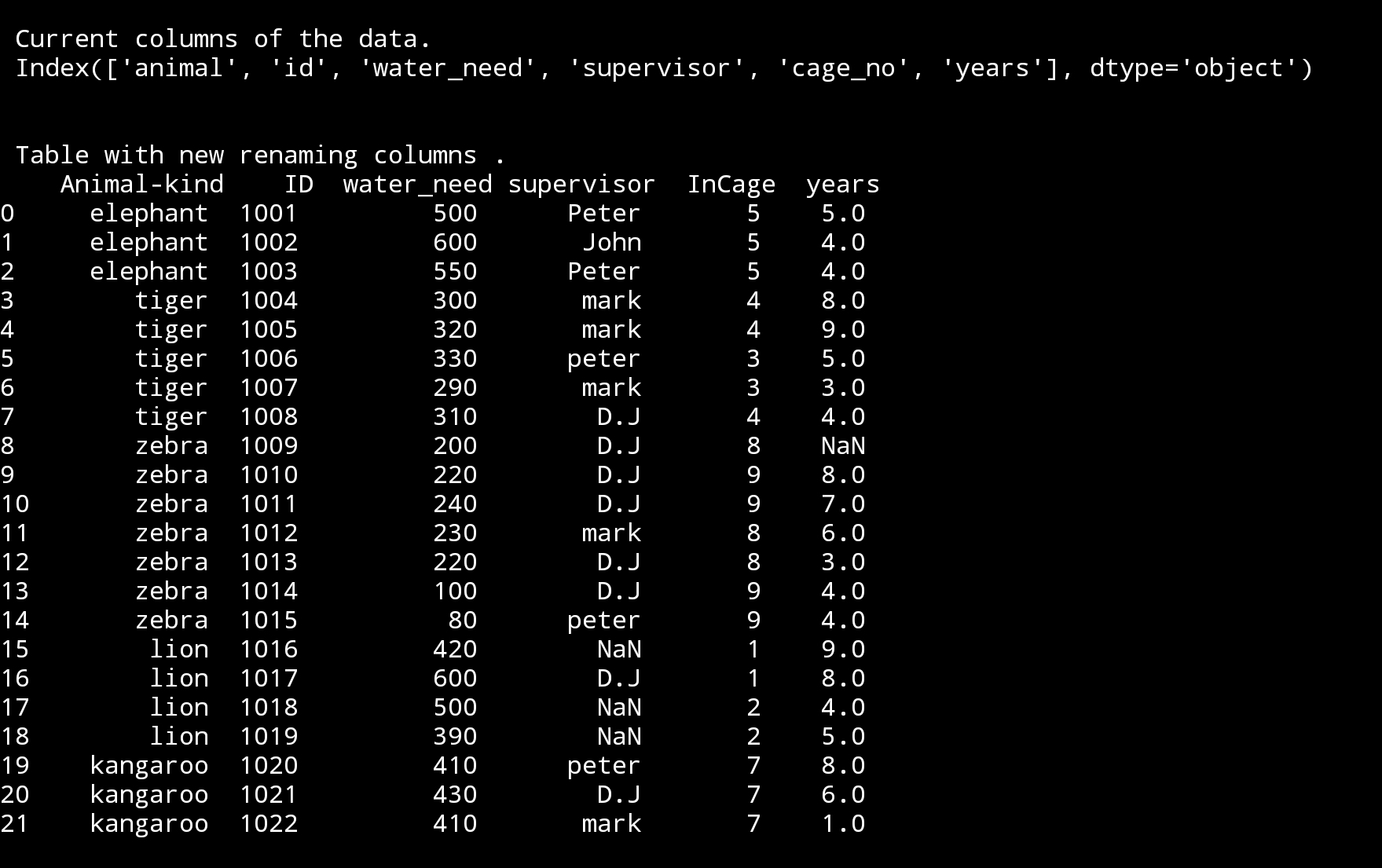
|
I just forgot to add .sample(6) so we will just have sample data, but anyway the new header is there and we use inplace = True so this new header will stay with us in df3.
Missing Data: This is the biggest challenge in any data file, some time the application that used to fills the form, or the person who entering the data or for any other reasons they are not handling the missing data in a standard way, so you may find just empty field, or ‘NA’ or dummy numbers like (0000), or (-0) or dashes (—). Handling such case is realy depending on the customer you are working for, like what they want to put/write in each empty field, now we are just talking about filling with standard key.
In coming code we are saying to pandas: whenever you found NaN replace it with ‘NA’
new_df=df3.fillna(‘NA’)
print(‘\n\n Replace NaN with NA.\n’new_df)
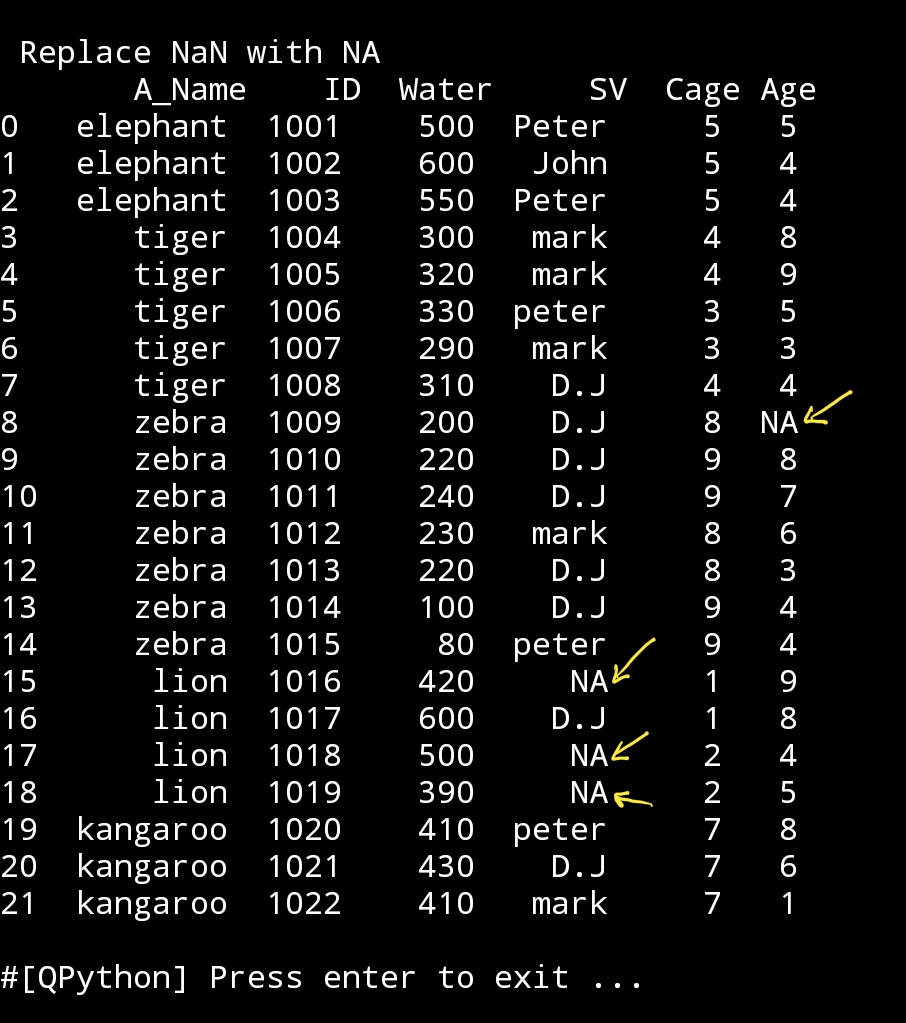
|
Note This: I will go to our data_file_zoo.csv and just add more NaN to some fields so our coming case will be meaningful.
Our data_file_zoo.csv has 6 columns, animal, id are primary keys and can’t be empty, so there MUST be filled. Now for the other columns I will say for each of columns if the data is NaN then we will replace it with:(MD:Missinf Data, NA:Not Available and – for numbers )
water_need : MD
supervisor : NA
InCage : –
years : –
Note That we MUST use the same columns name in the df we are working with.
Here is the code:
Replacing Missing Data
new_df=df2.fillna({‘water_need’:’MD’, ‘supervisor’:’NA’,’InCage’: ‘-‘ ,’years’:’-‘})
print(‘\n\n’,new_df)
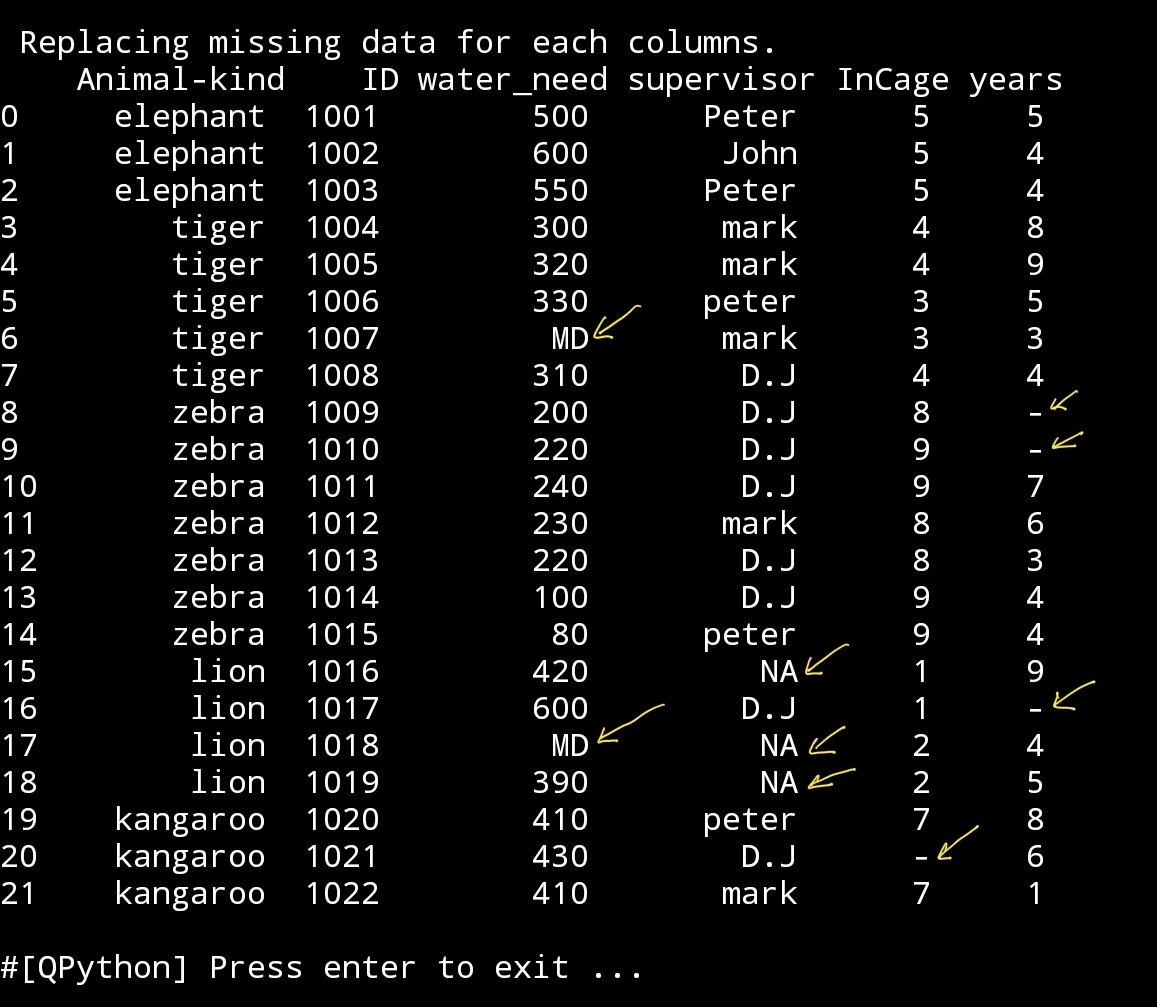
|
(I mark the replacing fields.)
Let’s say we notes that some data in water_need column is not logical, like if we know it can’t be 600, so we just want to replace any number biger that or equal to 600 in that column ot ‘err’. Code here..
Code to change some value based on a condition.
df2.loc[df2[‘Water’] == 600, [‘Water’]] = ‘err’
print (‘\n\n change 600 to err./n’,df2)
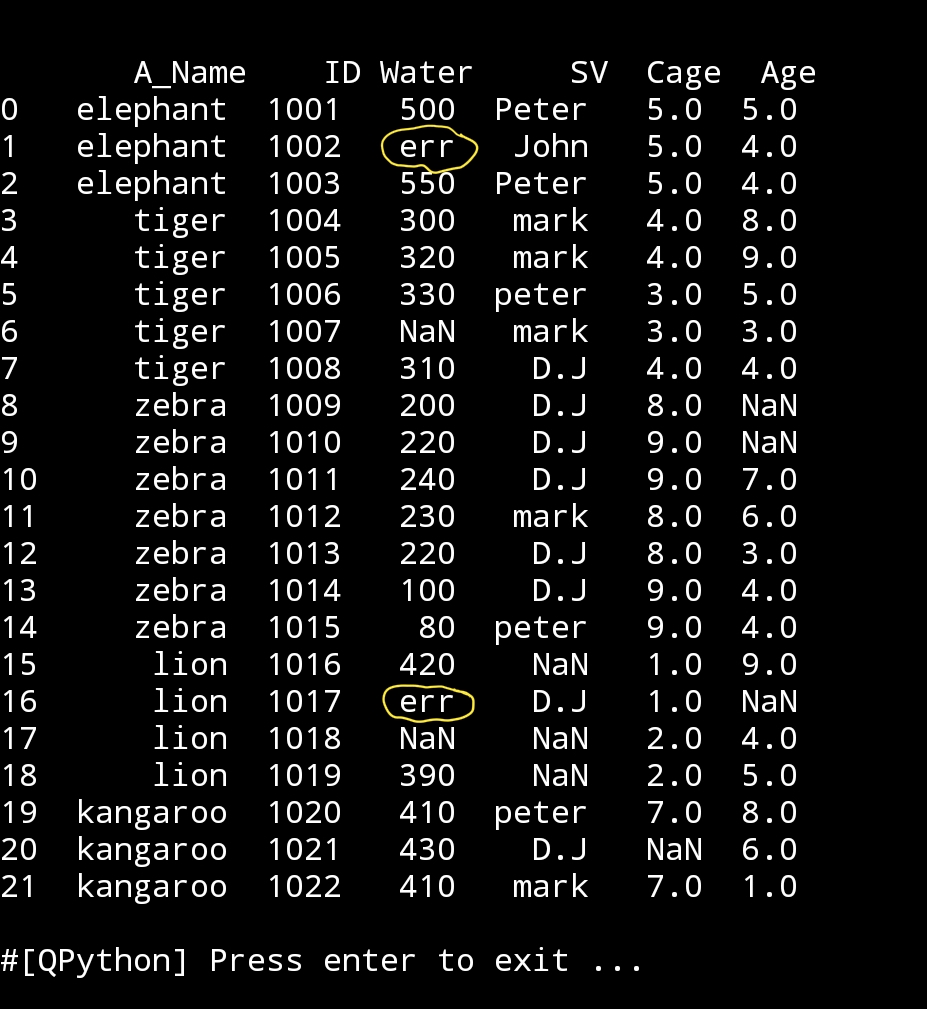
|
:: Pandas Lessons Post ::
| Lesson 1 | Lesson 2 | Lesson 3 |
| Lesson 4 | Lesson 5 |
 Follow me on Twitter..
Follow me on Twitter.. Taking pictures is not my main daily practices, but when i start playing with my camera, i really enjoy my self.
Thanks for visiting my Space..



