Archive
Python: Shares Speculation System – Part 6
Learning : Python, DataBase, SQL, SQlite3
Subject: Plan, Design and Build a Shares Speculation System
Project Card:
Project Name: Shares Speculation System
By: Ali
Date: 2.7.2020
Version: V01-2.7.2020
In Part-5 we wrote the function to submit the Buying Transactions ..[Click to Read] also we wrote the section of showing/displaying the Buying records on the screen. In this part we will continu on same function to write the code to Save Selling Transaction and display them on the screen in Show all Transactions Function.
So First we will writing the code to Save/Submit Selling Transactions. Now let’s start coding ..
Before we start I want to focus on a one-line If statement that we will use to give the user the ability or the chance to Quit or Exit from the function in any time before saving the Transaction by just entering ‘Q’, here is the code: if s_s_id in [‘Q’,’q’] : return (s_s_id is the user input).
In def sell_share(): function we will display all the Shares Name (by calling show_share() function) on the screen and ask the user to select the ID for the share, then we will Run tow SQL statements to get some data about that share such as it Full Name and the amount of shares we have (from s_basket table), if the return value of the s_basket is None or we Don’t have any shares we can’t do any Sell process so we will Exit. Here is the code ..
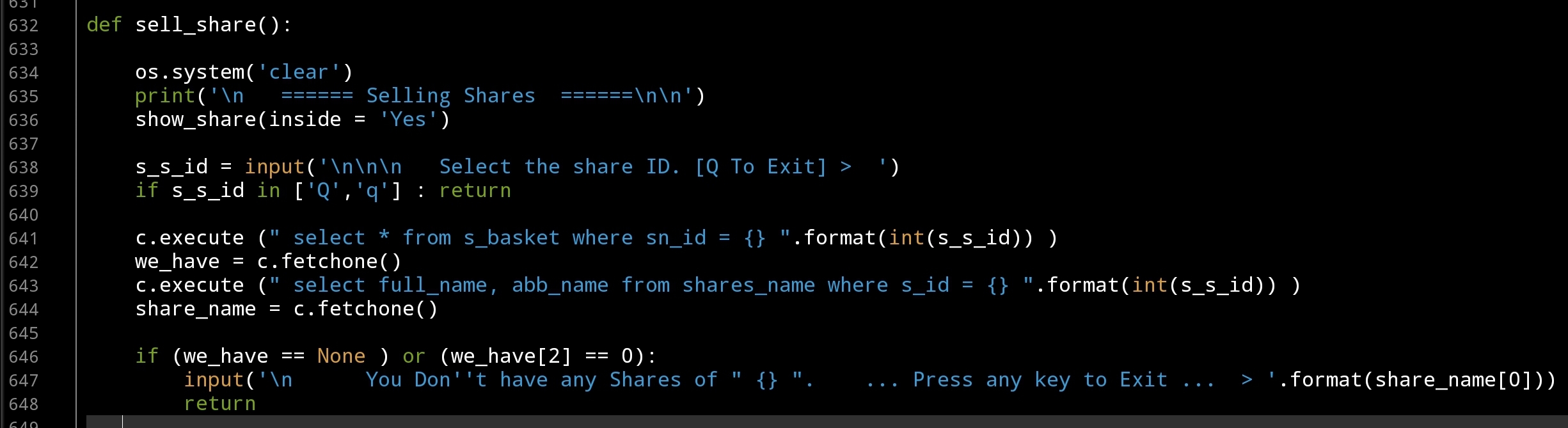 |
If we have shares, then we will print on the screen to show total amount of shares we have and will ask the user to Enter the new selling share information like the Date, The Amount of Selling and the Price, here is the code ..
 |
After that, we will ask the user to CONFIRM Saving by pressing ‘Y’, and will use the SQL Insert statement to submit the data to the Database, also to update the s_basket table…. Here is the code.
 |
Now we finish the def sell_share(): function and will start to writing the corresponding part to show the Selling Transactions in def show_all_trans ():, in this section of the code as we did to show the Buying Transactions we will RUN an SQL statement to get all selling transaction in the table, we will use the formatting to output the data as a table format. Here is the code
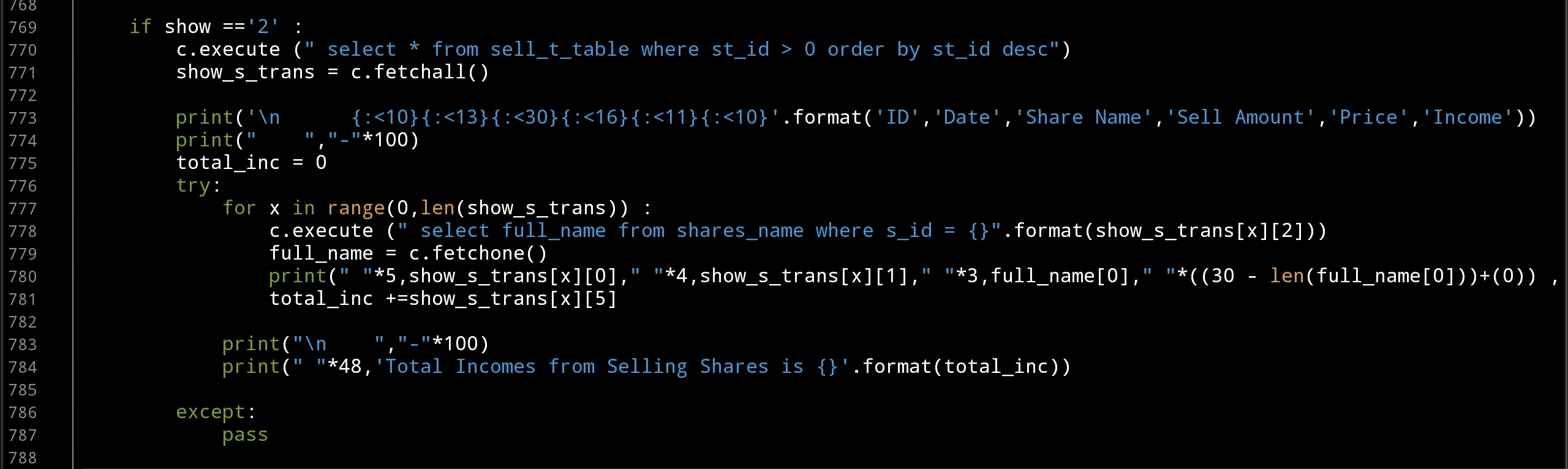 |
Coming Up: In Next part we will Write the Function to Delete Transactions from the System, also will write a code to Show All Transactions Buying and Selling in one Table.
[NOTES]
1. Part-1 has no code file.
2. We are applying some basic Validations on some part of the code, and assuming that the user will not enter a messy data.
3. This Application Purpose for Saving Transactions and NOT for Desetion Making and Dose’t Have any type of AI or ML Model to Predict the Prices and/or Giving Sugestions on Buying or Selling Shares.
:: Shares Speculation System ::
| Part 1 | Part 2 | Part 3 | Part 4 | Part 5 |
| Part 6 |
To Download my Python code (.py) files Click-Here
 Follow me on Twitter..
Follow me on Twitter..By: Ali Radwani
Python: Library Managment System -P3
Learning : Python, DataBase, SQlite
Subject: Create Simple Library Managment System
In this Part we will work on Classification Managment. As we know each book can fall in one or more subject or say ‘Classification’ then we can search for a book by it’s class, example of this, we may have classifications like: cook, computer, Health, History; also a book can have more than one classifications such as one book we gave it cook and sweet .. and so-on.
To do this we add another table to the project to hold all the Classifications and manage them. Here is the code ..
# New Table to be added.
sql_class = "CREATE TABLE if not exists classifi_list (class_id INTEGER PRIMARY KEY AUTOINCREMENT, class_name text )"
c.execute(sql_class)
db_conn.commit()
c.execute ("INSERT INTO classifi_list (class_id) VALUES(:class_id)",{"class_id":0})
db_conn.commit()
[NOTE: This code been added to the source file.]
Classification Managment: In Classification Managment we will have four Functions, and will write the codes to perform each function, also we will write the Menu Function to let the user select a function. Functions are:
1. Add New Classification.
2. Edit a Classification information.
3. Delete a Classification.
4. Show Classifications.
First: Here is the class_menu() Function, the user will have the prompt and asked to select an action or (9) to Exit.
# Classification Managment Fumction
def class_menu():
while True :
os.system('clear')
print('\n ====== LMS - Classification Managment ======')
print(' 1. Add New Classification.')
print(' 2. Edit a Classification information.')
print(' 3. Delete a Classification.')
print(' 4. Show Classifications')
print(' 9. Exit.')
user_choice = input('\n Select the Action you want from the Menu: ')
if user_choice == '1' :
# Function to Add New Classification
new_classification()
elif user_choice == '2' :
# Function to Edit a Classification information.
edit_classification()
elif user_choice == '3' :
# Function to Delete a Classification.
delete_classification()
elif user_choice == '4' :
# Function to Show a Classification.
show_classification()
elif user_choice == '9' :
return
Now, let’s start with Add New Classification. Simply we will ask the user to write a classification to be added to the Database, then we will check if it is already available in our Database, If yes then we will till the user so, or (if not available) we will add it, and will give the user the chance to add another one. If the user enter (Q or q) then we exit (Quit) from the function and return to the previous Menu.
# Function to Add New Classification
def new_classification() :
os.system('clear')
print('\n ====== Add New Classification ======')
while True :
class_name = input('\n Enter the Classification and Press Enter. [ To Exit Enter Q ].. > ').capitalize()
c.execute ("select * from classifi_list where class_name='{}'".format(class_name))
result = c.fetchone()
if class_name not in ['q','Q']:
if (result != None) :
print('\n We already have [{}] in the Classification Database. '.format(class_name))
else:
c.execute ("INSERT INTO classifi_list (class_name) VALUES(:class_name)",{"class_name":class_name})
db_conn.commit()
print('\n One Classification Added ... ')
else:
input('\n To Exit ... Press any key ..')
return
The Code |
Code, Run-Time |
Another Function to work on is Edit a Classification information In this one we will print-out all the Classifications we have and the user will select the one to Edit and will asked to Enter the ID number next to it. Then to Enter the New One and we will save it. Here is the code and the Out-put screen shot. To display all classifications on the screen we will use this code..
# Code to display the classifications on the screen
# First we list down all classifications.
c.execute ("select * from classifi_list where class_id > 0 order by class_name")
class_list = c.fetchall()
for cla in range (0,(len(class_list)-1),4):
try:
print('{:<3}{:<20}'.format(class_list[cla][0],class_list[cla][1]),end="")
print('{:<3}{:<20}'.format(class_list[cla+1][0],class_list[cla+1][1]),end="")
print('{:<3}{:<20}'.format(class_list[cla+2][0],class_list[cla+2][1]),end="")
print('{:<3}{:<20}'.format(class_list[cla+3][0],class_list[cla+3][1]))
except:
pass
[NOTE: We use the try: except to avoid any (index out of range) errors.]
Code |
Code, Run-time  |
Next we will work on the Delete a Classification, Deleting may effect on some Books that uses that classification, so we need to till the user to confirm Deleting. Also we will use the same code to list down all the classifications and ask the user to enter the ID of the one to-be Deleted. Here is a part of the code to Delete a classification..
# Part of the code ..
del_class = input('\n\n To Delete a Classification Enter it''s ID number [Q To Exit] > ')
if del_class not in ['Q','q'] :
c.execute ("select * from classifi_list where class_id = '{}' ".format(int(del_class)))
c_to_del = c.fetchone()[1]
print('\n Are you sure you want to Delete "{}" Classification? '.format(c_to_del))
print(' This action may effect on books has this Classification.')
user_approve = input('\n If you are sure to Delete "{}" Press Y or N: > '.format(c_to_del))
if user_approve in ['y','Y'] :
c.execute ("delete from classifi_list where class_id = '{}' ".format(del_class))
db_conn.commit()
input('\n One Classification has been Deleted... Press any Key > ')
else:
input('\n\n You Select NOT to Delete the "{}" Classification, Press any key to go back.. '.format(c_to_del))
if input('\n Do you Want to Delete Another Classification? [Y,N] > ') in ['n','N'] :
return
else:
input('\n You Select to Exit .. Press any Key > ')
return
The Code |
Code Run-Time |
Last Function to work in this post is Show Classifications the function we will list down all the Classifications on the screen. Very easy one, here it is
# Show Classification Function
def show_classification():
os.system('clear')
print('\n ====== Show Classification ======')
print(' The List of Classifications We Have, Sort in Alphbatic\n')
c.execute ("select * from classifi_list where class_id > 0 order by class_name")
class_list = c.fetchall()
for cla in range (0,(len(class_list)-1),4):
try:
print('{:<3}{:<20}'.format(class_list[cla][0],class_list[cla][1]),end="")
print('{:<3}{:<20}'.format(class_list[cla+1][0],class_list[cla+1][1]),end="")
print('{:<3}{:<20}'.format(class_list[cla+2][0],class_list[cla+2][1]),end="")
print('{:<3}{:<20}'.format(class_list[cla+3][0],class_list[cla+3][1]))
except:
# just in case error, pass and do nothing.
pass
input('\n\n ... Press any Key ..')
Code |
Code Run-time |
What’s Coming In coming post, we will write the Functions to Manage the Authors.
[ NOTE ]
1. I am using Galaxy Tab and QPython3 App.
2. All the above codes are available in the Download Section/Page under the project name.
3. The application codes, Functions, Menus and other parts of the Application are subject of changes. In case of changes I will mention that.
:: Library Managment System ::
| Part 1 | Part 2 | Part 3 | |
To Download my Python code (.py) files Click-Here
By: Ali Radwani
Python: Library Managment System -P2
Learning : Python, DataBase, SQlite
Subject: Create Simple Library Managment System
The Data: In the Part-1 we Talk about the Entities that we will create and about the Data we will collect (Fields). So here we are writing them again and we will add classification for each book :
Books Entity: Book Name, Book Author, Date of publish, Edition Number, Book classification number.
Author Entity : Author name, Author Nationality, email, SMA (social media account).
From the Author information we can see that we need to define a new Entity to hold the SMA.
SMA Entity: SMA Name, SMA Link.
Class Entity: class Name.
Here is each entity and field :
book:
- b_id integer PK
- b_name text,
- b_a_id integer,
- b_isbn text,
- b_dop text,
- b_ed integer
author:
- a_id integer PK
- a_name text
- a_email text
sma:
- sma_id integer PK,
- a_id integer,
- sma_name text,
- sma_link text
class:
- class_id integer PK
- class_name text
Now we will write the code to create the Database and set a connection
# create the Database and set a connection
import sqlite3, os
# Create the data-base & name it as LMS.
db_conn = sqlite3.connect ("LMS.db")
# set the connection.
c = db_conn.cursor()
Now we will create the tables..
# Function to create the tables
def create_tables_() :
# to create tables.
sql_books = "CREATE TABLE if not exists books (b_id INTEGER PRIMARY KEY AUTOINCREMENT, b_name text, b_a_id integer,b_isbn text, b_dop text, b_ed integer)"
sql_author = "CREATE TABLE if not exists author (a_id INTEGER PRIMARY KEY AUTOINCREMENT ,a_ name text, a_email text )"
sql_class = "CREATE TABLE if not exists classifi_list (class_id INTEGER PRIMARY KEY AUTOINCREMENT, class_name text )"
sql_b_class = "CREATE TABLE if not exists b_class (b_class_id INTEGER PRIMARY KEY AUTOINCREMENT, b_id integer, class_id integer )"
sql_sma = "CREATE TABLE if not exists sma (sma_id INTEGER PRIMARY KEY AUTOINCREMENT, a_id integer,sma_name text, sma_link text)"
c.execute(sql_books)
db_conn.commit()
c.execute(sql_author)
db_conn.commit()
c.execute(sql_class)
db_conn.commit()
c.execute(sql_b_class)
db_conn.commit()
c.execute(sql_sma)
db_conn.commit()
input('\n .. LMS Tables created.. Press any key .. ')
After creating the tables, and to make sure that AUTOINCREMENT of Primary key will run we need to have a number in each PK field, to do that we will add a 0 (Zero) record to each table. Here is the code to do it ..
#Function to Insert the Zero Record
#Function to Insert the Zero Record.
def insert_record_0():
c.execute ("INSERT INTO books (b_id) VALUES(:b_id)",{"b_id":0})
c.execute ("INSERT INTO authors (a_id) VALUES(:a_id)",{"a_id":0})
c.execute ("INSERT INTO classifi_list (class_id) VALUES(:class_id)",{"class_id":0})
c.execute ("INSERT INTO b_class (class_id) VALUES(:class_id)",{"class_id":0})
c.execute ("INSERT INTO sma (sma_id) VALUES(:sma_id)",{"sma_id":0})
db_conn.commit()
input('\n ...Dummy records been Inserted .... Press any key .. ')
The above functions create_tables_() and insert_record_0() will be run only one time to create the tables, and insert record number ZERO. During the programming and coding we may need to delete the DataBase and re-created again, in that case we run the both functions again.
Create the Menus
As we side, each Entities will have three Main Functions [Add, Edit, delete ad search]. Let’s start with Main Menu.
Main Menu Code |
Main Menu Run-Time |
Book Menu, Code |
Book Menu, Run-Time |
Author Menu, Code |
Author Menu, Run-Time |
Classification Menu, Code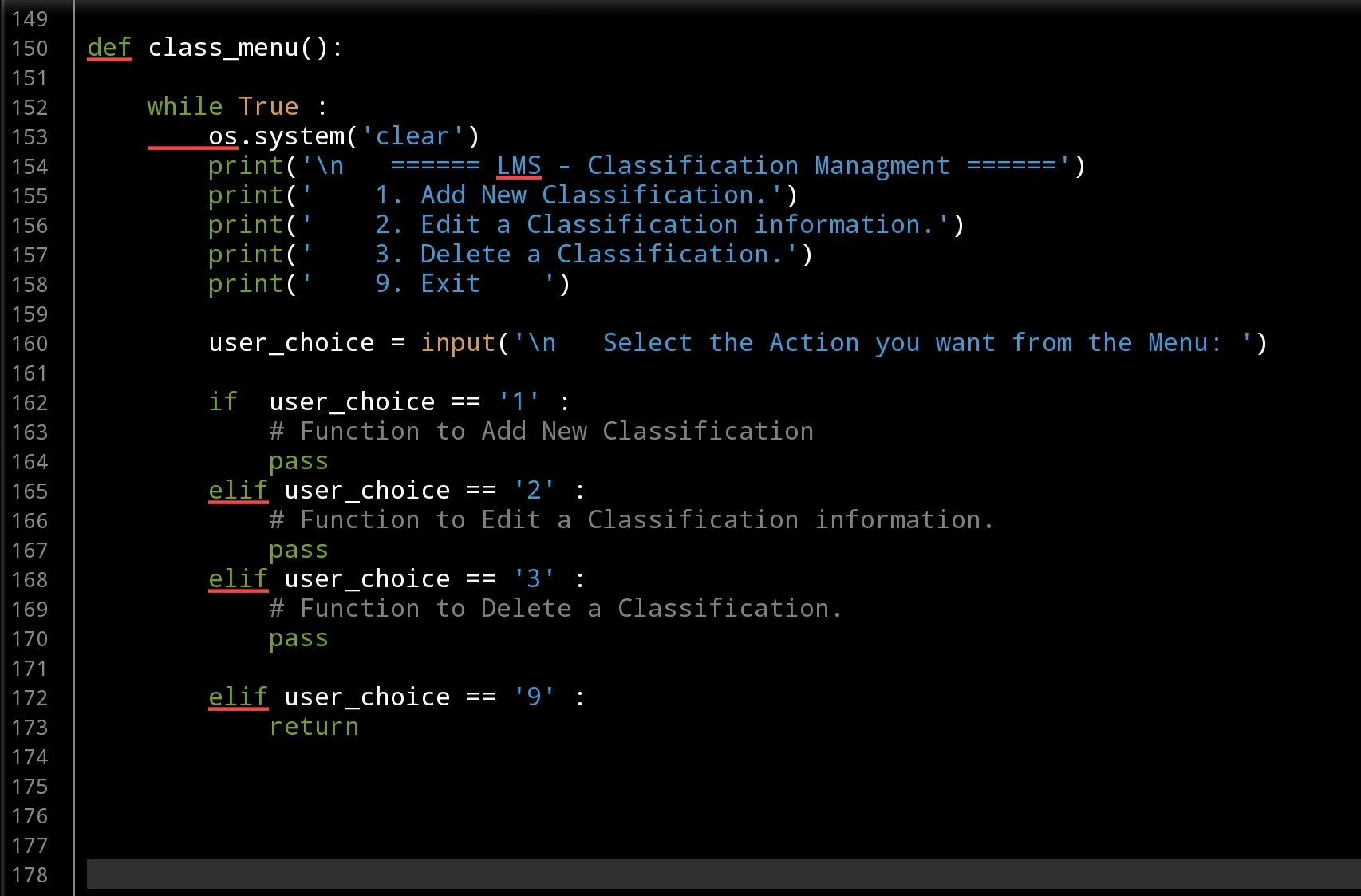 |
Classification Menu, Run-Time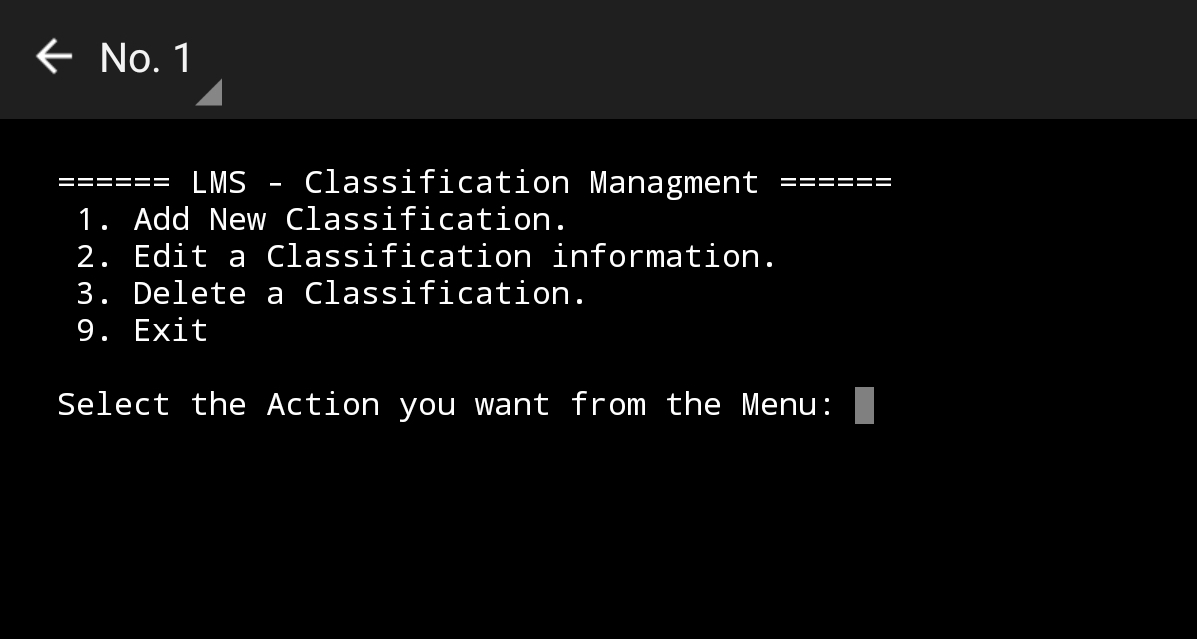 |
Search Menu, Code  |
Search Menu, Run-Time 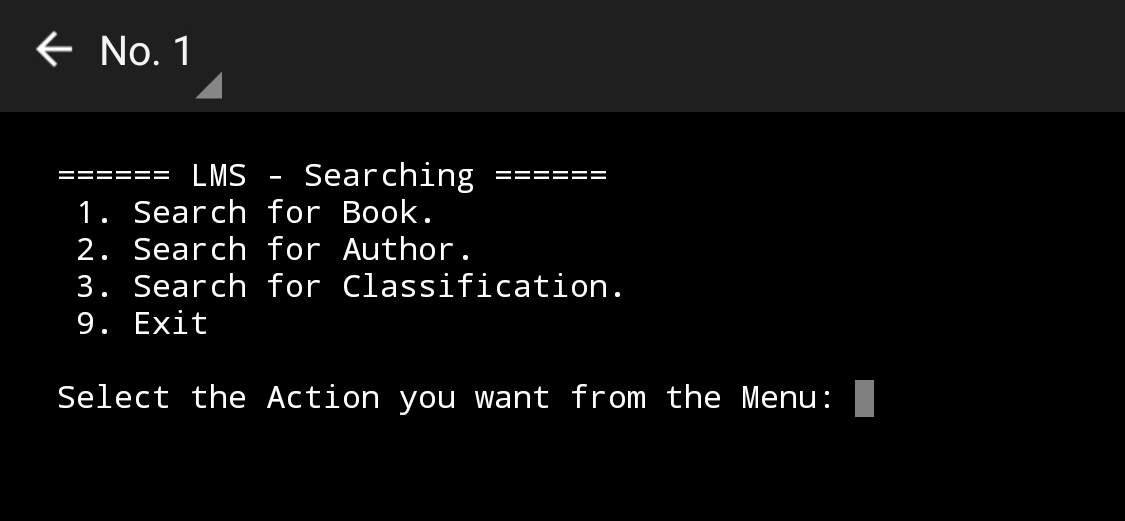 |
What’s Coming In coming post, we will write the Functions to Manage the Authors and Classifications.
[ NOTE ]
1. I am using Galaxy Tab and QPython3 App.
2. All the above codes are available in the download section/page under the project name.
3. During the progress of the project, we may need to Add, Edit or delete any Tables, Fields, Menus or Functions that we had already finished.
:: Library Managment System ::
| Part 1 | Part 2 |
To Download my Python code (.py) files Click-Here
By: Ali Radwani
Python: Library Managment System -P1
Learning : Python, DataBase, SQlite
Subject: Create Simple Library Managment System
Details: The project is to Plann, design and builed a simple Library Managment System LMS (For Books), the main Functions in the system are: (In this Version 1)
- Add New Book.
- Edit an exsit Book.
- Delete a Book.
- Search.
Planning: In this step we need to sit with the Business owner to identify the problem and plann the project. Since we will work as Fullstack (mean we will do every thing) and this is a training session project, we will be the Business owner of the project and will talk about the problem.
The Problem: In a very simple way, we have some Books and we want a System to store the books in a way that we can retrieve it’s basic information such as Title, Author, Subject and other information about it. Also we need to do some basic search to get statistics about our Library.
Data Gathering: First we need to define the Data we want to stoe, as we are talking about a simple Books Library System we can predict this very easily by looking to a book that we have and write-dowan the keys part of the book we want to store.
In this project we have three main Entities : Books, Authors, Borrowers. In this version (V.01) of the project we will NOT cover the borrowing functionality. So we will store the following data:
Books Entity: Book Name, Book Author, Date of publish, Edition Number, Book classification number.
Author Entity : Author name, Author Nationality, email, SMA (social media account).
From the Author information we can see that we need to define a new Entity to hold the SMA. SMA Entity: SMA Name, SMA Link.
To Manage our System we will write Four main functions for each entity:
ADD, Edit, Delete and search.
Part 2: In Part-2 we will create the tables (The Entities), Insert the Zero-Row and create the Main Menu for each Entities.
:: Library Managment System ::
| Part 1 | Part 2 | Part 3 | Part 4 |
To Download my Python code (.py) files Click-Here
By: Ali Radwani
Python: SQlite Project – P3
Learning : Python and Sqlite3
Subject: Sqlite3, Database functions ” Employee App” P3
In this post we will cover the SEARCH AND EDIT Functions, so let’s start with Edit.
To Edit or change something or a record in the database we need to target that line of record; and to do this we will select the record by it’s Primary-Key. In our employee table the primary-key is emp_id. Our scope is to list-down all the data to the user and he will enter the ID of the employee, then we will ask about each field if he want to change it, and we will assume that if he just press enter then NO CHANGE will be done to that field. So let’s see the Function in run also the code ..
| Once we select opt.4 in Main-Menu we will seea list of all records and the prompt |
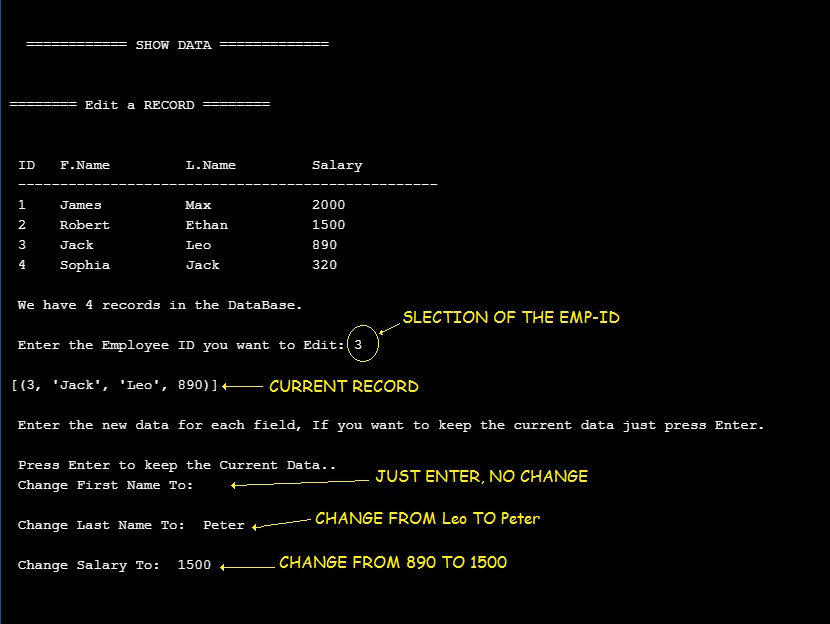 |
| Then the system will show the record after the change.. |
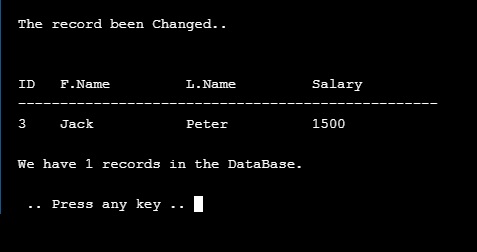 |
And here is the code ..

|
Now we will write a basic SEARCH function, usually searching (in a simple apps) will be for one of the fields in the DataBase, in our case we have employee First Name, Employee Last Name and the Salary. In the Search section we will ask the user to select a searching key (fname, lname or Salary) then to enter the value to be search for and running our SQL-Query based on that. Let’s see.
First here is the run screen, Once we select Search from Main-Menu we will jump into Search Page, with short list to select from, in this sample I select the 1. First Name (search key), then the prompt will wait for the user to Enter the Name and retrieve the record ..
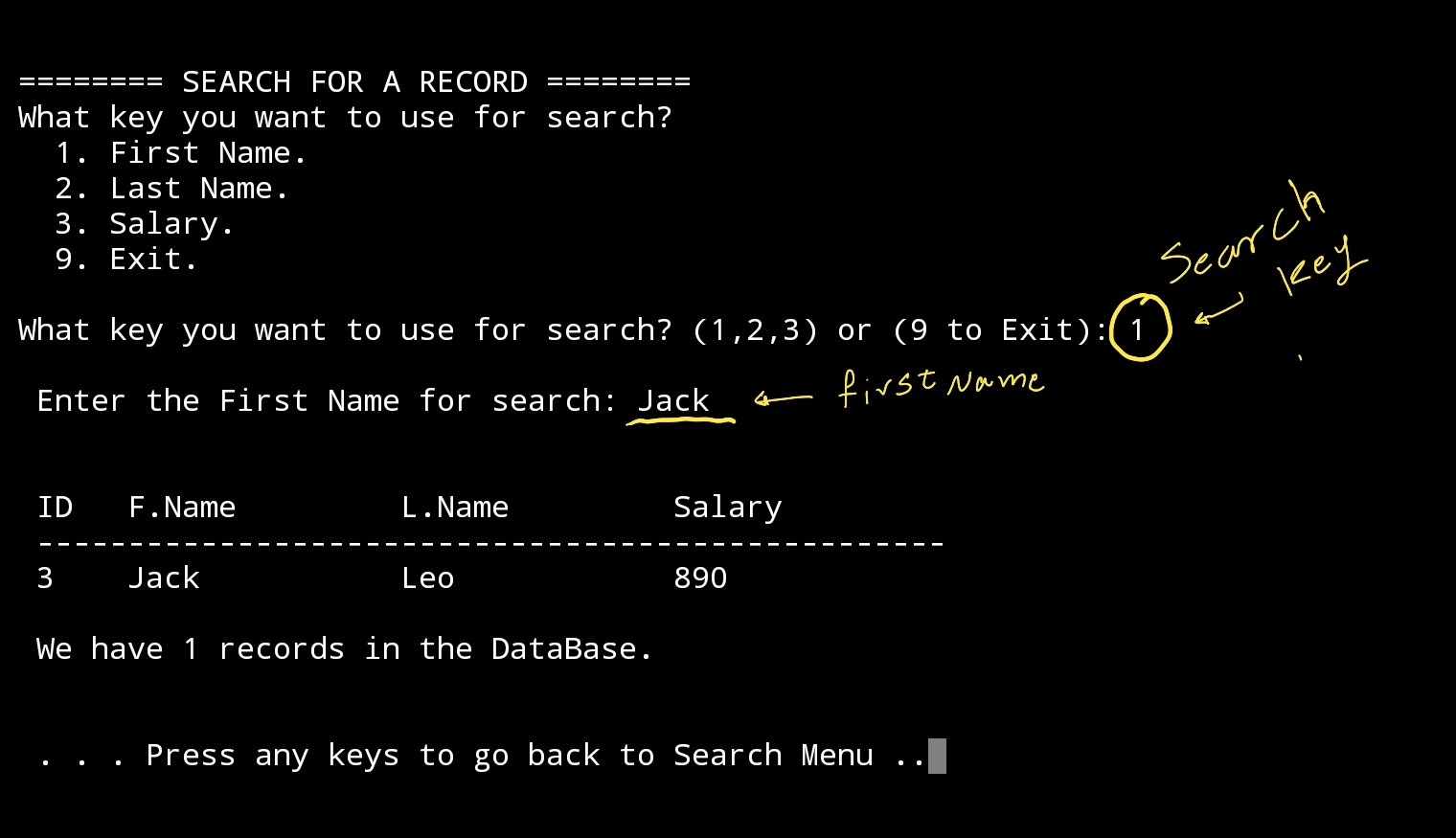
|
Here I select to search with Last Name, and i got two records ..
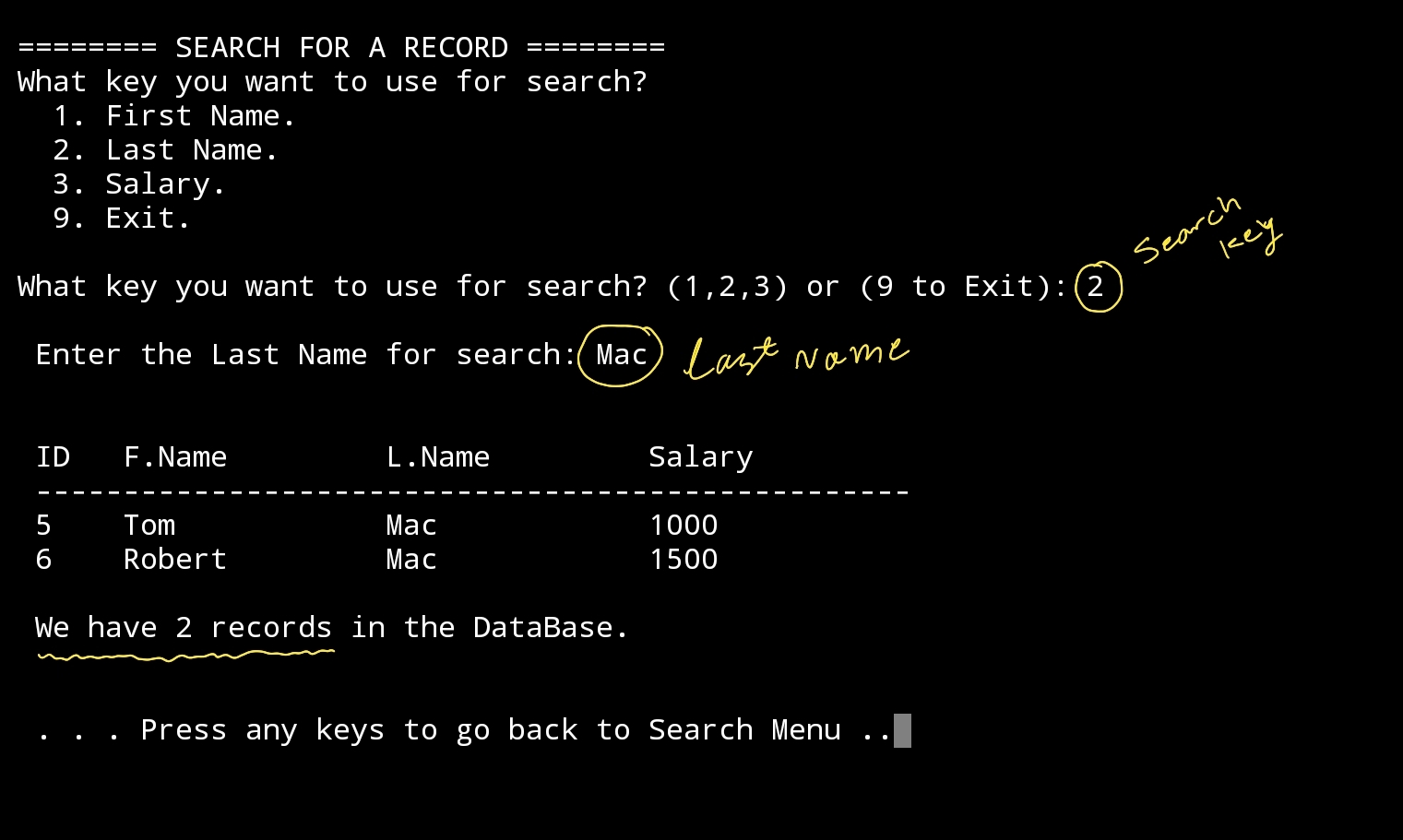
|
For the Salary we will have two options, even to fetch all the records with same salary amount the user will enter, or the user can enter a range for the salary (From and To). Let’s see the run-screen for it.
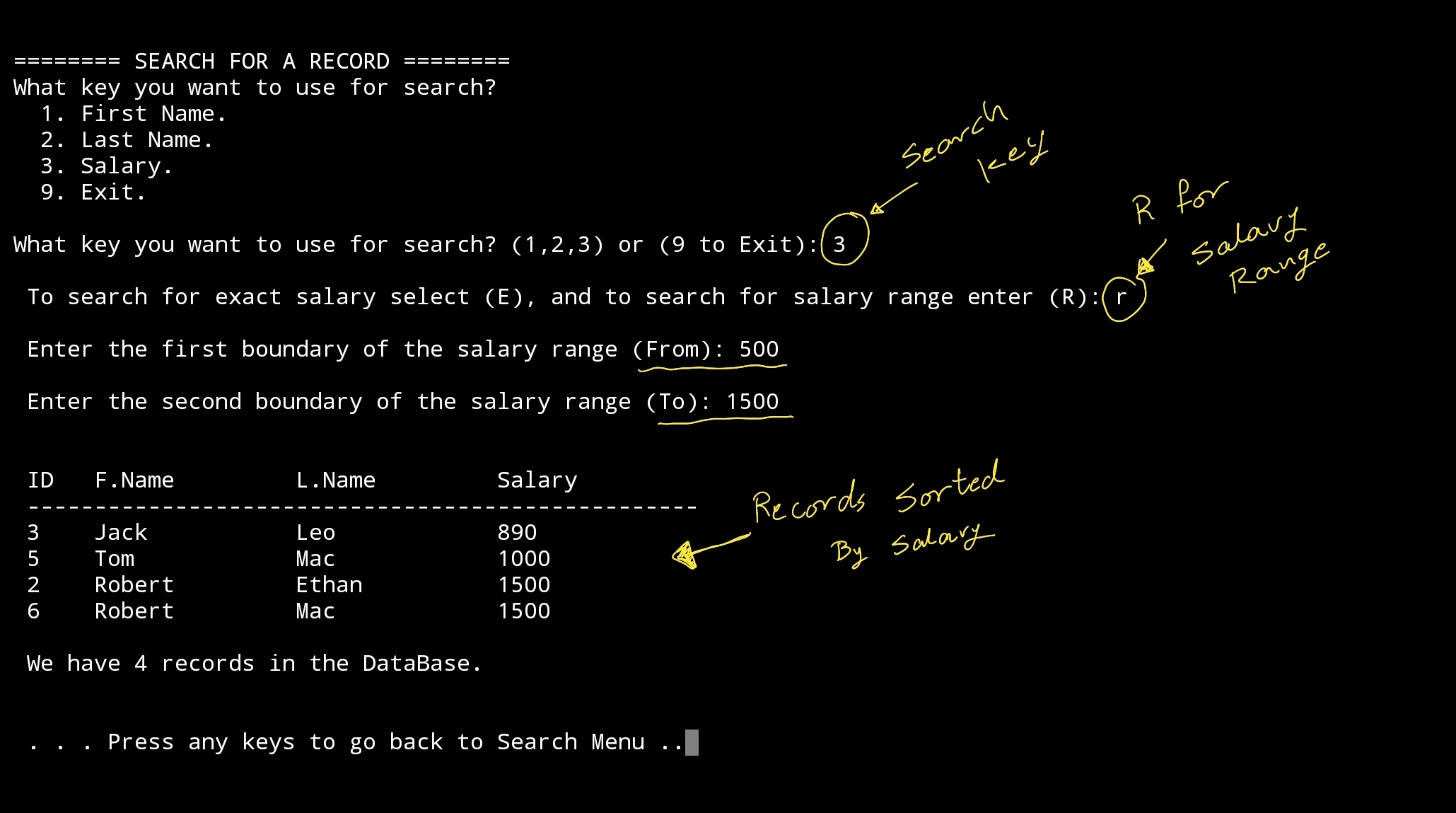
|
We can see that 4 records has the salary between (500 and 1500) also we sort the records by salary. |
Last thing here is a screen-shot of the code ..

|
By this paragraph we reach the end of this simple application, we work full-stack, we design the database, Table and create it, also we design the application Menus and Functions. If we run the application we may find some small issues that need to be enhanced or changed, but in general the Main Goal was to write a simple application working with DataBase and using SQlite.
To Download my Python code (.py) files Click-Here
By: Ali Radwani
Python: Applications Main Menu
Learning : Application Main Menu
Subject: Main Menu Template
In some of my applications often I start writing codes to create a Menu for some parts in the app. Now in this post we will write a simple general Main Menu Template, to keep the screen prompt waiting for the user we use while True, and to exit we just use return . Here is the code ..

|
'''
Date: 10.1.2020
By: Ali Radwani. www.ahradwani.com
Main_Menu Function
'''
import os
def main_menu():
"""
Template Function to help in creating a Menu for the application.
You can change the names and functions must be defined.
"""
while True:
os.system("clear")
print('\n ===========[ MENU NAME]=============')
print(' --------------------------------------')
print(' 1. Function-1 Name.')
print(' 2. Function-2 Name. ')
print(' 3. Function-3 Name')
print(' 9. Exit')
uinp= input('\n Enter your Selection: ')
if uinp == '1':
Function_1_Name()
elif uinp == '2':
Function_2_Name()
elif uinp == '3':
Function_3_Name()
elif uinp =='9':
return
else:
print('\n Please select from the Menu.'
To Download my Python code (.py) files Click-Here
By: Ali Radwani
Python: SQlite Project – P2
Learning : Python and Sqlite3
Subject: Sqlite3, Database functions ” Employee App” P2
In Part1 of this project (Click to Read) we create the database and set the connection, also we create an Employee table with very basic fields and also we wrote a dummy_data() function to Insert some records into the table. And to make the application usable we wrote the Main-Men function and we test it with selecting to display the records that we have.
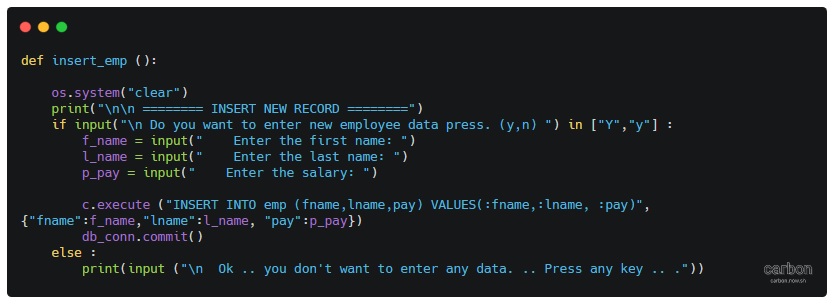
Today we will write other functions from our Menu. INSERT NEW EMPLOYEE: To Insert new employee we will ask the user to input or to fill the fields we have in our table such as First Name, Last Name and the Salary. .Let’s see the code ..
# Insert Function
def insert_emp ():
os.system("clear")
print("\n\n ======== INSERT NEW RECORD ========")
if input("\n Do you want to enter new employee data press. (y,n) ") in ["Y","y"] :
f_name = input(" Enter the first name: ")
l_name = input(" Enter the last name: ")
p_pay = input(" Enter the salary: ")
c.execute ("INSERT INTO emp (fname,lname,pay) VALUES(:fname,:lname, :pay)",{"fname":f_name,"lname":l_name, "pay":p_pay})
db_conn.commit()
print(input ("\n One record has been Inserted. .. Press any key .. ."))
else :
print(input ("\n Ok .. you don't want to enter any data. .. Press any key .. ."))

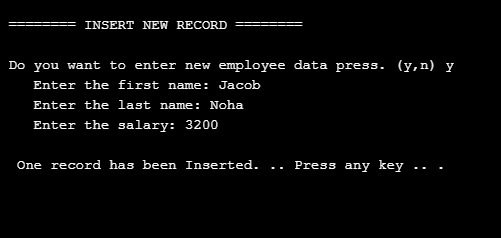
So, if we select to Insert a new Employee and we Enter First name as : Jacob Last Name as: Noha also we we set the salary to 3200 and press Enter, as in this page ..
|
Then if we select to show all data we have in the database, we can see the new record added..
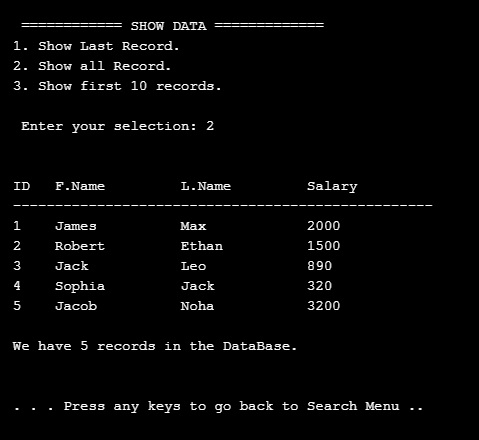
|
DELETE AN EMPLOYEE: To Delete or remove an employee from the database, First we will print-out all the records on the screen and ask the user to enter the ID_ number of the employee he want to delete. As shown here ..
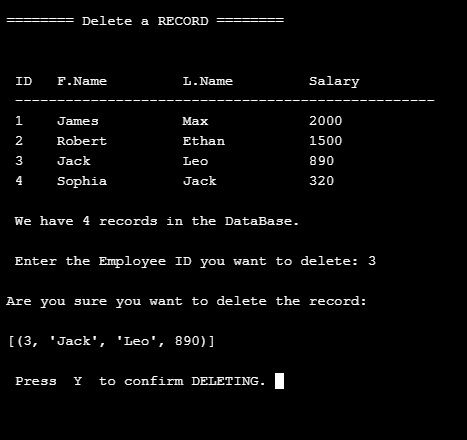
|
In the above example we select ID number 3 to be deleted and press enter, the system will show the record and ask to confirm the deletion and wait for ‘Y’ to be pressed, then the record will be deleted.
..Here is the code..

|
In this post we cover the INSERT AND DELETE of the records from the database, in the next post we will cover the SEARCH AND EDIT Functions also some search conditions like salary range and group-by command.
To Download my Python code (.py) files Click-Here
By: Ali Radwani
Python: My Fake Data Generator P-7
Learning : Python: Functions, Procedures and documentation
Subject: About fake data P-7: (Fake File Name)
In this post we will write a function to generate a file name. Each file name consist of two part, first one is the name which present (or should present) a meaning part, then there is a dot (.) then mostly three characters showing the file type or extension.
Scope of work: Our files names will have 4 syllables all to gather will be one file name. Each syllables will be loaded in a variable as shown ..
1. fext: for Files extensions such as: (doc, jpeg, pdf, bmp …. and so on)
2. name_p1: Is a noun such as (customers, visitors, players .. . and so on )
3. name_p2: will be an nouns, adjective or characteristics such as (name, index, table .. .. and so on)
4. Then we will add a random integer number between (1,30) to give the file a version, or a number.
All parts or syllables will be as one file name.
Let’s Work: First we need to load the File name syllables from the json file called : file_dict.json
# Loading the json from a url
import json , requests, random
fname = "https://raw.githubusercontent.com/Ali-QT/Ideas-and-Plan/master/file_dict.json"
def call_json_url(fname):
"""
Function to load the json file from URL.
Argument: str :fname
Return : dict: data
"""
req = requests.get(fname)
cont = req.content
data = json.loads(cont)
return data
fdict = call_json_url(fname)
# Save each syllables into variable.
f_ext = fdict["fext"]
f_p1_name = fdict["name_p1"]
f_p2_name = fdict["name_p2"]
Now we will write the function that will generate the file name:
# Function to generate the file name
def generate_fname():
"""
Function to generate a Fake files name.
File Name consist of four syllables, Two names, a random number and an extension.
First two syllables of the file name will be selected randomly from a dictuenary stored in a json file.
Return : str : f_file_name
To read the information key in the json file use this code.
------ CODE TO READ DATA-SET INFORMATION --------------
for each in fdict["information"]:
print(each,":",fdict["information"])
---END OF CODE ------------------------------------------
"""
fp1 = (random.choice (f_p1_name)["n_p1"])
fp2 = (random.choice (f_p2_name)["n_p2"])
fp3 = (random.choice (f_ext)["ext"])
f_file_name = (fp1 + "_" + fp2 + "_" + str(random.randint(1,30)) + "." + fp3)
return f_file_name

|
Last thing we just will call the function for X numbers of files Name we want.
# Generate 15 file Name.
for x in range (15):
generate_fname()
[Output]:
kids_name_15.ico
speakers_list_1.asp
cars_photos_27.csv
students_database_26.xml
kids_details_27.html
animals_index_10.mov
speakers_parameters_17.csv
drivers_name_8.doc
males_attributes_16.mov
players_sketches_11.py
animals_sketches_3.wav
cars_details_12.css
animals_list_17.txt
flowers_parameters_4.doc
players_database_28.log
:: Fake Function List ::
| Function Name | Description |
| Color | To return a random color code in RGB or Hex. |
| Date | To return a random date. |
| Mobile | To return a mobile number. |
| Country | To return a random country name. |
| City | To return a random City name. |
| ID | To return X random dig as ID. |
| Time | To return random time. |
| Car’s Brand | |
| file_name | file name: list for fake file names. |
| Creatures | Random animal names of a certain type: Mammals, Birds, Insect, Reptiles |
| Foods | To return a random list of foods |
By: Ali Radwani
Python: My Fake Data Generator P-4
Learning : Python: Functions, Procedures and documentation
Subject: About fake data P-4: (Fake Dates)
The fourth function of our Fake Data Generator will be the date function, from it’s name this one will generate a FAKE Date in yyyy/mm/dd format. The function will have one argument (go_back) for range, the max-limit is current date (today) and mini-limit will be (1/1/1900), if the user did’t pass any thing for (go_back) then the range is (from current to 1/1/1900) and if the user pass (X) then the range will be ((current date) to current – X_YEARS). Also in dates we need to take care of Leap Years, In leap year, the month of February has 29 days instead of 28. To solve this in our function we can use two ways, first one (the easy way) we know that we are generating a random numbers for months and days; so we can say if the month is February, then days can’t be more than 28. But if we want this thing to be more realistic we need to add more conditions such as :
1. The year can be evenly divided by 4.
2. If the year can be evenly divided by 100, it is NOT a leap year, unless the year is also evenly divisible by 400. Then it is a leap year (February has 29 days).
'''
10/12/2019
By: Ali Radwani
To get Fake Date.
'''
import random, datetime
def fdate(go_back = 0):
"""
### Fake Date Generator V.01 ###
Date: 10.12.2019, By: Ali Radwani
This function will generate and return a fake date in string format.
The function accept one int argument go_pback.
If go_past = X, and current year - X is less than 1900 then
the range of FAKE time will be (current year to current year - X).
If NO argument passed to the function, then default limit set to 1900.
Default limits: Date are from current (today) and back to 1900.
Import: random, datetime
Argument: int : go_back to set the upper limit of the date
Return: str: dd/mm/yyyy
"""
# Get current year.
c_year = datetime.datetime.today().year
# set the maximum year limit.
if go_back > 0 :
max_y_limit = c_year - go_back
else :
max_y_limit = 1900
if max_y_limit < 1900 :
max_y_limit = 1900
yy = random.randint(max_y_limit, c_year)
mm = random.randint(1,12)
if mm in [1,3,5,7,8,10,12] :
dd = random.randint(1,31)
elif mm in [4,6,9,11]:
dd = random.randint(4,30)
else :
# IF the month is February (2)
if (yy % 4 == 0 ) or ((yy % 100 == 0)and (yy % 400 == 0)):
# It is a leap year February has 29 days.
dd = random.randint(1,29)
else : # it is NOT a leap year February has 28 days.
dd = random.randint(1,28)
d = (str(dd) +'/'+ str(mm)+'/' + str(yy))
return (str(dd) +'/'+ str(mm)+'/' + str(yy))
# To check the output.
for x in range (30):
print(fdate())
<
Here is a screenshot of the code, also available on the Download Page . . .

|
:: Fake Function List ::
| Function Name | Description |
| Color | To return a random color code in RGB or Hex. |
| Date | To return a random date. |
| Mobile | To return a mobile number. |
| Country | To return a random country name. |
| City | To return a random City name. |
| ID | To return X random dig as ID. |
| Time | To return random time. |
| Car’s Brand | |
| file_name | |
| Done |
By: Ali Radwani
Python: My Fake Data Generator P-2
Learning : Python: Functions, Procedures and documentation
Subject: About fake data P-2: (Fake ID)
Before we start i’d like to mention that with our last fcolor() function we write some comments in the first part of the function between three double quote(“””), and if we load the function and call help() as help(fcolor()) we will get that information on the python console as a help as in screen shot.

|
In this post we will write a function to generate a fake ID number, for ID’s there could be several styles, sometime we just want a random number without any meaning; just X number of random digits. Most of the time we need this number to be mean-full based on certain rules. For example, in Banks they may use some digits that indicate the branch. In sport club, they may include the date … and so-on.
Here we will write a function called key_generator(), the function will take two arguments (dig, s) dig is your key digits number, s is the style, if s = d then the first 6 digits of the key will be the date as ddmmyy + random digits, and if s = anything else or s not passed then the key will be as default (just x-digits). Let’s see the code.
First the summary or say information about the function:
def key_generator(dig, s = 'n'):
"""
### Date: 8/12/2019, By: Ali Radwani ###
Summary:
This function will generate x-digit key randomly.
If the argument s = 'd' or 'D' then the key is two part, first (6) digits
are date as ddmmyy then x-digit random numbers.
If the argument s anything else than ['d','D'] or no argument passes, then the key
is random numbers without any meaning.
The numbers will randomly be selected in range of (10 to 99).
import: random, datetime
Argument: int: dig: The number of digits for the key.
str: s : The key style (with date or just random numbers)
return: int: the_key
"""
Now, if the user pass s=’d’ then part of the key will be the current date, to do this we will call the datetime function in python and split it into dd,mm,yy. Here is the key_generator() function.
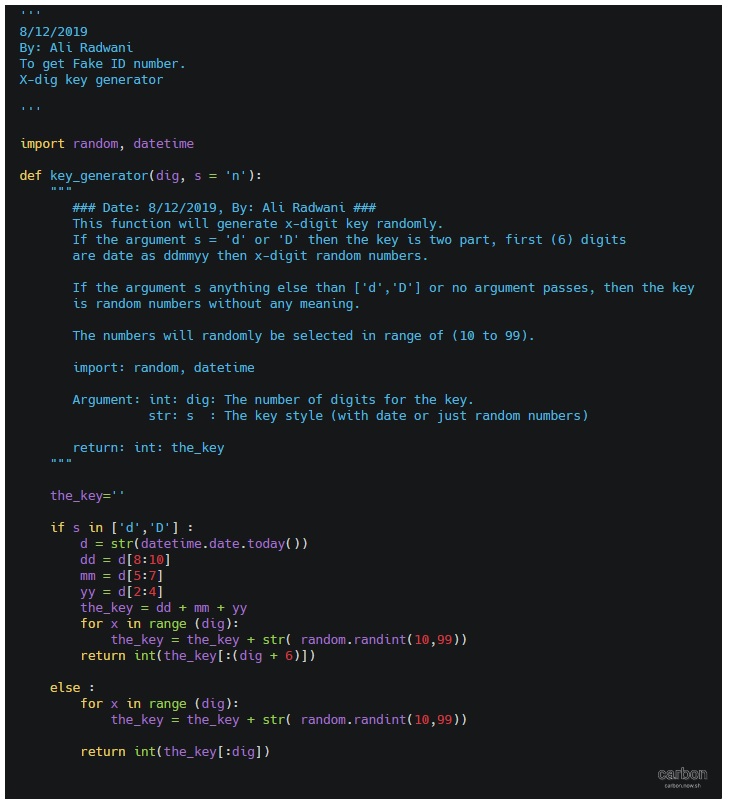
def key_generator(dig, s = 'n'):
"""
### Date: 8/12/2019, By: Ali Radwani ###
Summary:
This function will generate x-digit key randomly.
If the argument s = 'd' or 'D' then the key is two part, first (6) digits
are date as ddmmyy then x-digit random numbers.
If the argument s anything else than ['d','D'] or no argument passes, then the key
is random numbers without any meaning.
The numbers will randomly be selected in range of (10 to 99).
import: random, datetime
Argument: int: dig: The number of digits for the key.
str: s : The key style (with date or just random numbers)
return: int: the_key
"""
the_key=''
if s in ['d','D'] :
d = str(datetime.date.today())
dd = d[8:10]
mm = d[5:7]
yy = d[2:4]
the_key = dd + mm + yy
for x in range (dig):
the_key = the_key + str( random.randint(10,99))
return int(the_key[:(dig + 6)])
else :
for x in range (dig):
the_key = the_key + str( random.randint(10,99))
return int(the_key[:dig])
|
In next Fake Data function we will try to write one to generate the date. It will be published on next Sunday.
:: Fake Function List ::
| Function Name | Description |
| Color | To return a random color code in RGB or Hex. |
| Date | To return a random date. |
| Mobile | To return a mobile number. |
| Country | To return a random country name. |
| City | To return a random City name. |
| ID | To return X random dig as ID. |
| Time | To return random time. |
| Done |
By: Ali Radwani
Taking pictures is not my main daily practices, but when i start playing with my camera, i really enjoy my self.
Thanks for visiting my Space..



