Python: Pandas more commands
Learning : Pandas more commands
Subject: DataFrame Simple Statistics
In this post we will just go through some commands in pandas that related to simple statistics of dataframe, in coming table first we will list down all the commands then will see each in cation.
| Function | Description |
| 1. sum() | Get the sum of the value |
| 2. cumsum() | cumsum() is used to find the cumulative sumvalue over any axis. Each cell is populated with the cumulative sum of the values on upper cells. |
| 3. count() | counting the NaN in the DataFrame. |
| 4. mean() | |
| 5. median | |
| 6. std() | Standard deviation measures the spread of the data about the mean value. |
| 7. max() | Return the maximum value in each column. |
| 8. min() | Return the minimum value in each column. |
| 9. prod() | Return the value of product operation of the items in the column. (works only for number columns) |
| 10. Cumprod() | Return the number in the cell * all the cells over it. |
| 11. abs() | Returns the absolute value of the column and it is only applicable to numeric columns. |
| 12. mode() | It returns the most repeated value in the column. |
1. sum() Using command as: print(df.sum()) it will return a sum of columns, if contain numaric then it will be a normal sum, if it is string return a string contain all as one string without spaces.
In our cas (data_file_zoo) the only practical result is the water-need where it represent the total amout of water we need in our zoo. So to get the sum of one column we can write it as: df[column name].sum()
print(‘\n\n Total amout of water we need is: ‘, df[‘water_need’].sum())
|
|
2. cumsum() Using command as: print(df.cumsum()) cumulative sumvalue will return the number in the cell + the sum of all the cells over it, we may need this function in a data analysis.
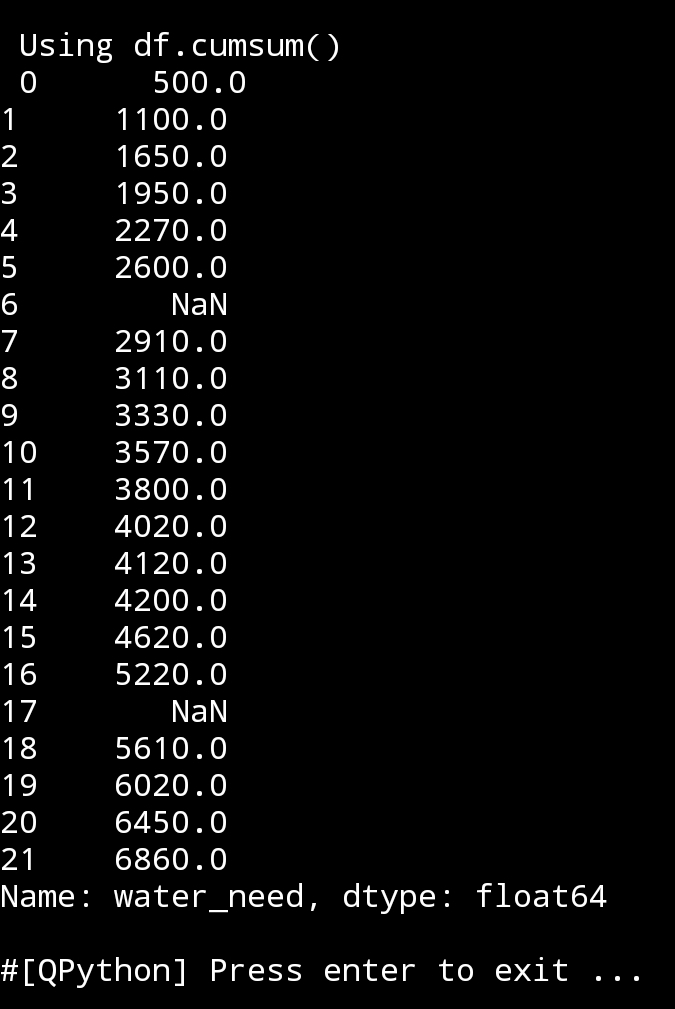
|
3. count() Using command as: print(df.count()), this function gives us the total data in each columns, so we know how many NaN or empty cells are in our table.
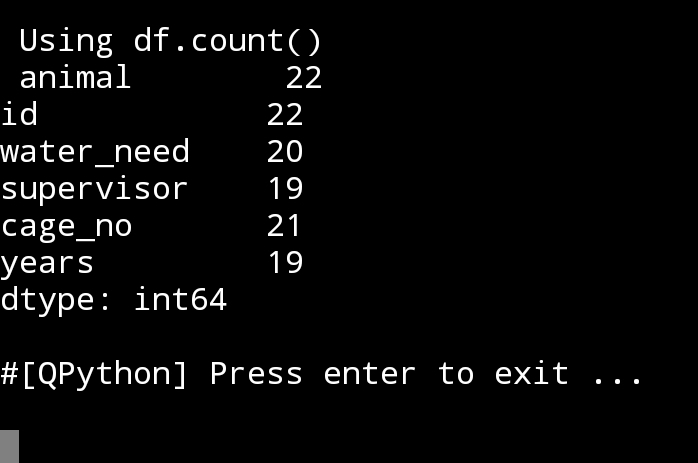
|
4. mean() Using command as: print(df.mean()), Thw Arithmetic Mean is the average of the numbers in the df for each columns.
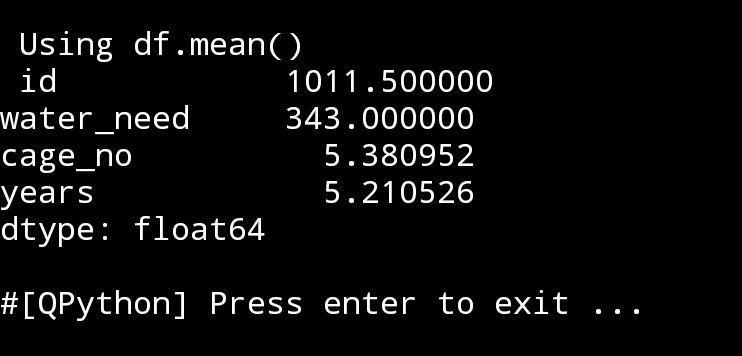
|
5. median() Using command as: print(df.mediam()), in a sorted list
median will return the middle value, If there is an even number of items in the data set, then the median is the mean (average) of the two middlemost numbers. We can get the median of the specific Column.
# median of water_need column..
print(‘\n\n Median of the Water Need: ‘,df.loc[:,”water_need”].median()
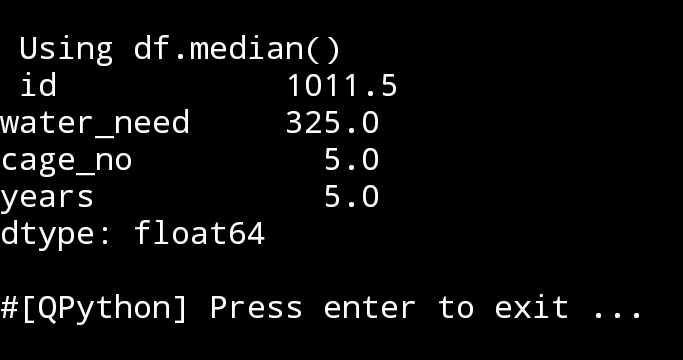
|
6. sdt() Using command as: print(df.std()), it is the Standard deviation of the dataframe, or columns in the df.
The standard deviation measures the spread of the data about the mean value. It is useful in comparing sets of data which may have the same mean but a different range. In our example here (zoo file) some functions is not given the meaning that we may need, but if we have a data from statistical modeled or other scientific field this std() sure will be helpful.
7. max() Using command as: print(df.max()), return the maximum value in each column. If we want the max. value in a specific column then we use theis code:
print(‘\n\n’,df.loc[:,”water_need”].max())
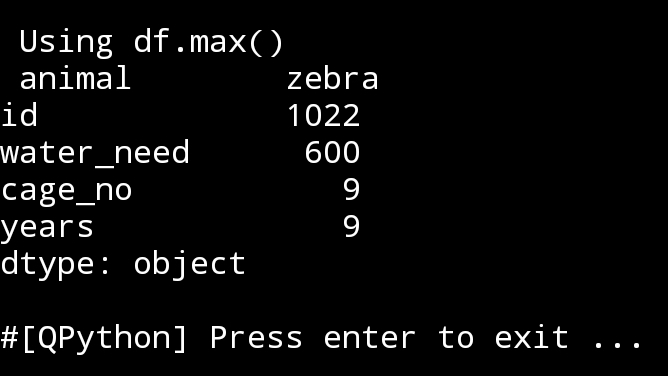
|
8. min() Using command as: print(df.min()), same as max, the min() will return the minimum value in the df for each column, and we can get the min for only one column by using:
print(‘\n\n’,df.loc[:,”water_need”].min())
9. prod() Using command as: print(df.prod()), return the value of product operation of the items in the column. (works only for number columns)
10. cumprod() Using command as: print(df.cumprod()), cumulative product will return the number in the cell * all the cells over it.
To show this i will use a Series of numbers and apply cumprod.
cumprod()
some_value = pd.Series([2, 3, 5, -1, 2])
print(‘\n\n some_value in a column.\n’,some_value)
print(‘\n\n some_value.cumprod()\n’,some_value.cumprod())

|
11. abs() Using command as: print(df.abs()), It returns the absolute value of the column and it is only applicable to numeric columns.
12. mode() Using command as: print(df.mode()), It returns the most repeated value in the column.
Find the most repeated value:
print(‘\n\n Function: df.count()\n’,df.mode())
# mode of the specific column
df.loc[:,”animal”].mode()
:: Pandas Lessons Post ::
| Lesson 1 | Lesson 2 | Lesson 3 | Lesson 4 |
| Lesson 5 |
 Follow me on Twitter..
Follow me on Twitter.. Taking pictures is not my main daily practices, but when i start playing with my camera, i really enjoy my self.
Thanks for visiting my Space..



