Archive
Python Project: Properties Maintenance System P7
Subject: Writing a Full Application for Properties Maintenance System [Property: Showing the Records in Main property Table]
Learning : Python, Math, SQL, Logeic
[NOTE: To keep the code as simple as we can, We WILL NOT ADD any user input Varevecations. Assuming that our user will Enter the right inputs.]
After adding Records to the Main Property Table, we need to display the records on the screen. So now in this part (Part -7) we will write a function to display all the records. The Function name will be def show_property() the function is not taking any attribute and is Not returning any things. First we will print-out the Table-Header then we will run an [SQL: select * from table-name] command to fetch all the records, then will [for loop] and test-format to print all the records on the screen. Here is the Code ..
 |
After i display the records, I notes that the Address-Column needs more than one row (in some cases), and it miss the line formating, so I wrote a function and call it def warp_text(tex,warp_on,nl_space) the function takes three arguments, the test: it the text/string you want to print.warp_on: is a number of character before the new-line.nl_space: is the number of white-character in the new-line.
Here is the Code ..
# Function to warp
def warp_text(tex,worp_on,nl_space) :
c = 0
for t in range (len(tex)) :
print(tex[t],end="")
c += 1
if c == worp_on :
print('\n', ' '*nl_space, end="")
c = 0
Check all the codes in the Download Page..
End of Part 7
NOTE: If you Download this Part you MUST Run the Option 82 (82. Delete the Data-Base and Start Again.) from the Main Menu to do the following Updates:
- Update the properties_t Table (Adding the number of BathRooms)
- Update on create_tables Function.
- Update on insert_zero_records Function.
If you did this in last part (6) then you don’t need to do it again
In Part-8 In the Next Part, after adding and showing the records we will write the Function to Delete a record from the Table.
:: PMS Parts ::
| Part 1 | Part 2 | Part 3 | Part 4 |
| Part 5 | Part 6 | Part 7 | Part 8 |
..:: Have Fun with Coding ::.. 🙂
To Download my Python code (.py) files Click-Here
 Follow me on Twitter..
Follow me on Twitter..By: Ali Radwani
Python Project: Properties Maintenance System P6
Subject: Writing a Full Application for Properties Maintenance System [Add New Property Functions]
Learning : Python, Math, SQL, Logeic
[NOTE: To keep the code as simple as we can, We WILL NOT ADD any user input Varevecations. Assuming that our user will Enter the right inputs.]
This is Part-6 of an Application to Manage Properties Maintenance in this part we will writ a Function to Add New Property to our System.
Add New Property:
This May be the longest Function in our system, we will ask the user to Enter the Data for a New Property and then saving it to the DataBase.
Simple Validation: In this Function we will do a very simple check on the user inputs, and will keep this as simple as we can so the code will not be long. Sample on this Validation will be if the user enter [E or e] we will exit the process and stop the Function.
Code Part Sample: In asking the user to select the property Type were we are using a look-up table for the Property Types, we will use the Function def get_lookup_values(tname,t_id,key_id): were we passing the table-name, the ID column name and the ID of the data we want to retrieve. Another code part we may see is checking the user input of the p_type_id (MUST BE NUMERIC)
if (p_type_id.isalpha()):
input(‘\n You Must Enter a Numeric Value. Press any key to Try Again .. > ‘). Also we can see the part of the code that will make sure that the user did not enter the [E to Exit] (if the user enter E we will display a message then will return to the Menu-Page)p_bedrooms = input(‘\n Enter the Number of Bedrooms in the Property. [E to Exit] > ‘)
if p_bedrooms in [‘e’,’E’] :
input (‘\n You Select to Exit .. Press any Key. >’)
return
Saving the Record:
After the user Enter all the data we need we will display it on the screen and asking for a confirmation to Save the record, If the user Enter [Y] as Yes, we will use the “INSERT INTO properties_t …” SQL command to save the Record to the dataBase.
Here is a screen-shot of the all code of the Function,
 |
NOTE: If you Download this Part you MUST Run the Option 82 (82. Delete the Data-Base and Start Again.) from the Main Menu to do the following Updates:
- Update the properties_t Table (Adding the number of BathRooms)
- Update on create_tables Function.
- Update on insert_zero_records Function.
In Part-7 In the Next Part we will write the Function to Display/Show all the Records of the Main-Property-Table on the screen.
:: PMS Parts ::
| Part 1 | Part 2 | Part 3 | Part 4 |
| Part 5 | Part 6 | Part 7 | Part 8 |
..:: Have Fun with Coding ::.. 🙂
To Download my Python code (.py) files Click-Here
By: Ali Radwani
Python Project: Properties Maintenance System P4
Subject: Writing a Full Application for Properties Maintenance System [Property Type Functions]
Learning : Python, Math, SQL, Logeic
[NOTE: To keep the code as simple as we can, We WILL NOT ADD any user input Varevecations. Assuming that our user will Enter the right inputs.]
In Part-4 We will writing the Functions to Manage the Maintenance Property Types Functions. Property Type is a Look-up Table that will help the user to select some values, as other Look-up Tables, in Part-1 when we set-up the application and select to create the database we Insert some data in to it. Now will will write three Functions to Add New Property Type, Edit a Property Type and Delete a Property Type from the DataBase.
[.. ALL THE CODE ARE AVAILABLE IN DOWNLOAD PAGE.. ]
Starting with Add New Property Type, We will ask the user to write the New Property Type then will run the SQL command to Insert it into the data-base.. Hear is the Code ..
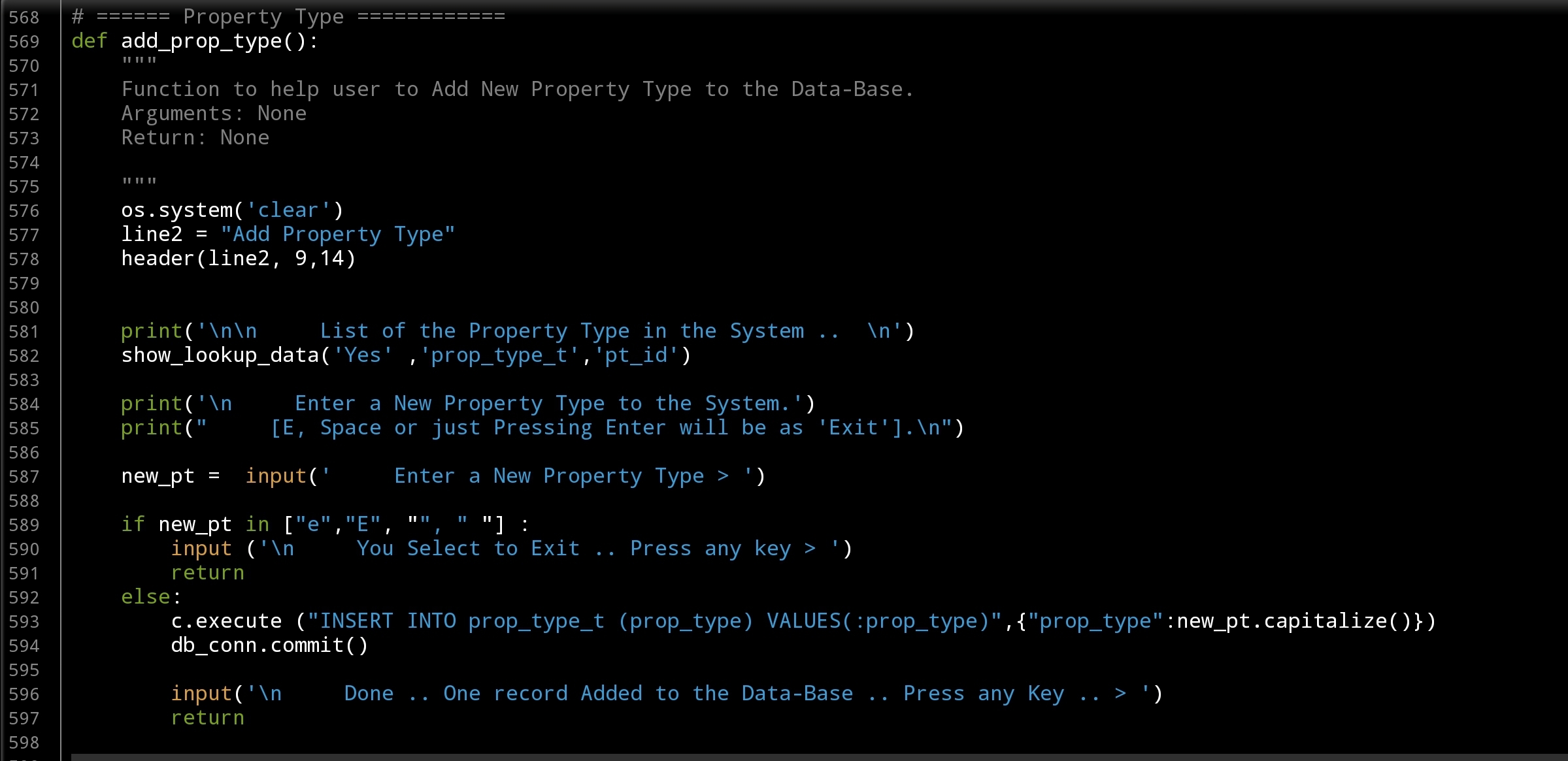 |
Now we will write the Edit Function we if we have any error in the typpiing of the Property Type we can correct it using this Function.. Fisr we will display all the Properies Type we have, asking the user to Select an ID of the one to-be Edit, then we will check for the availability of the user input [simple valitation proccess] and will ask the user to Insert the correct Value/Text to replace the exsist one. Here is the code ..
 |
The Last Function in this part is to Delete a selected Property Type, in this Functioin we will List down all the Property Types we have in the data-base and ask the user to select the ID for the one to be deleed, then we cal the SQL commands that will Delete the record. Here is the code ..
 |
.. DONE WITH PART – 4 ..
In Part-5 In coming post we will continue writing Lookup Table Functions to Add, Edit and Delete there data.
:: PMS Parts ::
| Part 1 | Part 2 | Part 3 | Part 4 |
| Part 5 | Part 6 | Part 7 | Part 8 |
..:: Have Fun with Coding ::.. 🙂
To Download my Python code (.py) files Click-Here
By: Ali Radwani
Python Project: Properties Maintenance System P3
Subject: Writing a Full Application for Properties Maintenance System [Property: Job Status Functions]
Learning : Python, Math, SQL, Logeic
[NOTE: To keep the code as simple as we can, We WILL NOT ADD any user input Varevecations. Assuming that our user will Enter the right inputs.]
In Part-3 We will start writing the Functions to Manage the Maintenance Job Status Functions. Job Status is a Look-up Table that will help the user to select some values, by defualt when you install the application and select to create the database, [we talk about this in Part-1] we Insert some data in to it such as [Pending, Compelete, In-Progress]. Now will will write three Functions to Add New Job Status, Edit a Job Status and Delete a Job Status from the DataBase.
So, let’s start with Add New Job Status, We will ask the user to write the New Job Status then will run the SQL command to Insert it into the data-base.. Hear is the Code ..
 |
The second Function will be to Edit a Job-Status, in this case we will display all the Job-Status we have in the table, and ask the user to select the ID of the one to be Edited, then we will ask again to enter the new/updated one, and using UPDATE command in SQL we will update the record. Here is the code ..
 |
Last Function will be to Delete a record from the Job-Status Table. Here we also will ask the user to select an ID then to confirm the deleting action. Here is the code ..
 |
In Part-4 In coming post we will continue writing Lookup Table Functions to Add, Edit and Delete there data.
:: PMS Parts ::
| Part 1 | Part 2 | Part 3 | Part 4 |
..:: Have Fun with Coding ::.. 🙂
To Download my Python code (.py) files Click-Here
By: Ali Radwani
Python Project: Properties Maintenance System P2
Subject: Writing a Full Application for Properties Maintenance System
Learning : Python, Math, SQL, Logeic
[NOTE: To keep the code as simple as we can, We WILL NOT ADD any user input Varevecations. Assuming that our user will Enter the right inputs.]
In Part-2 we will start writing the Functions in our app, to start I select the Payment Methods, this is a Look-up Table that will help the user to select come values, by defualt when you install the application and select to create the database, [in Part-1] we Insert some data all lookup-tables, So here in payment Method we have [Cash, Card, Cheque]. Our Functions will be Add New Payment Method, Edit a Payment Method and Delete a Payment Method.
Once i start writing the Edit Function, i notes that we need another two Functions to Help-up theyare: get_lookup_values(tname,t_id,key_id) and check_availabilty(dt, d_id, check_id) both not printing any thing on the screen just returning a Value.
get_lookup_values(tname,t_id,key_id) Here we pass the Table-Name, the ID field and key_id we want to return it’s Value.
check_availabilty(dt, d_id, check_id) This function will return True if the ID we send in ‘check_id’ is in the Data-Table dt.
So, let’s start with Add New Payment Method, We will ask the user to write the New Payment Method the will run the SQL command to Insert it into the data-base.. Hear is the Code ..
# Add Payment Method
def add_pay_method():
os.system('clear')
line2 = "Add Payment Method"
header(line2, 9,14)
print('\n\n List of the Payment Methods in the System .. \n')
show_lookup_data('Yes' ,'pay_meth_t','pm_id')
print('\n Enter a New Payment Method to the System.')
print(" [E, Space or just Pressing Enter will be as 'Exit'].\n")
new_pm = input(' Enter a New Payment Method > ')
if new_pm in ["e","E", "", " "] :
input ('\n You Select to Exit .. Press any key > ')
return
else:
c.execute ("INSERT INTO pay_meth_t (p_method) VALUES(:p_method)",{"p_method":new_pm.capitalize()})
db_conn.commit()
input('\n Done .. One record Added to the Data-Base .. Press any Key .. > ')
return
Now, we will go to Edit a Payment Method that we have in the DataBase, here we will list all the Data we have on the screen, and will ask the user to Select the one to be edit, we will check the availability of the ID using the def check_availabilty(dt, d_id, check_id) Function and then [if the ID is available] we will use the def get_lookup_values(tname,t_id,key_id): function to fetch the key-value of that ID, then asking the user to Enter the New/Edited one. Here is the code..
 |
Last Function in this part is to Delete a Payment Method from the Databsae, here also we will display all the contents of the table on the screen, and ask the user to select the one tobe deleted, we will check the availability of the ID and ask the user to confirm the Deleting action, then will call the SQL command to delete the entry. Here is the code..
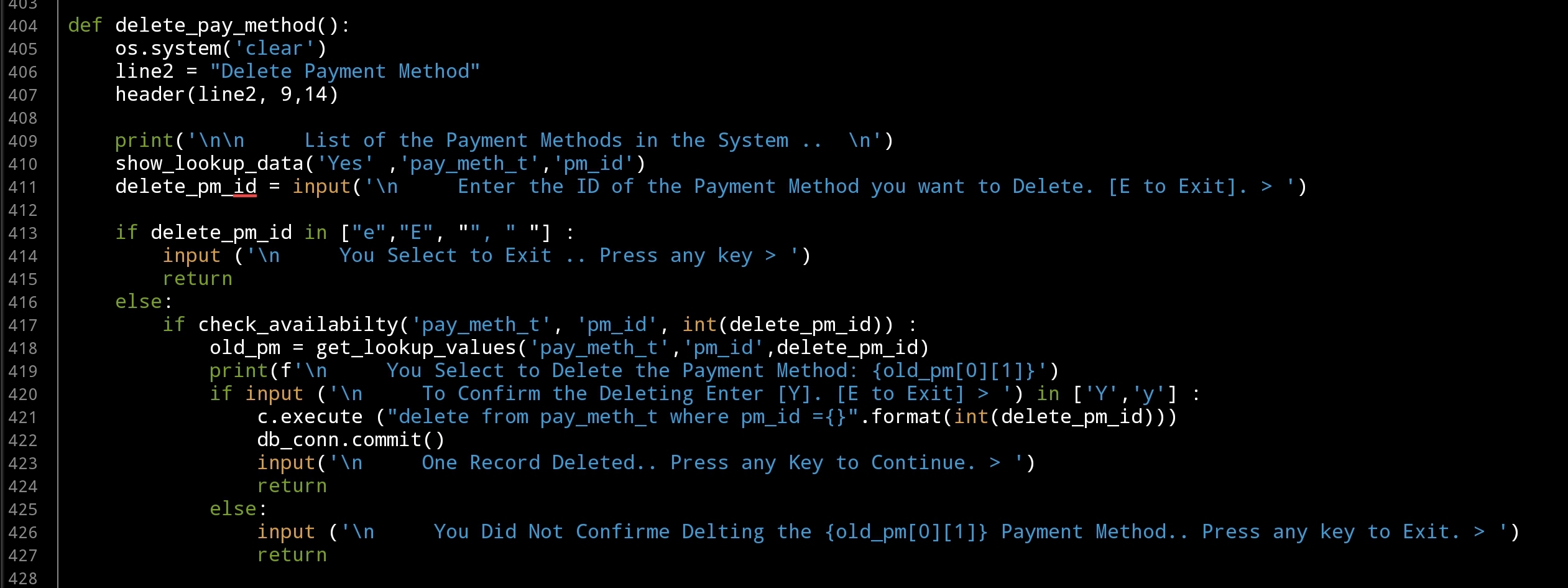 |
In Part-3 In coming post we will continue writing Lookup Table Functions to Add, Edit and Delete there data.
:: PMS Parts ::
| Part 1 | Part 2 | Part 3 | Part 4 |
..:: Have Fun with Coding ::.. 🙂
To Download my Python code (.py) files Click-Here
By: Ali Radwani
Python Project: Properties Maintenance System P1
Subject: Writing a Full Application for Properties Maintenance System
Learning : Python, Math, SQL, Logeic
[NOTE: To keep the code as simple as we can, We WILL NOT ADD any user input Varevecations. Assuming that our user will Enter the right inputs.]
In one of last week posts I mentioned that i am working on a New Project, and that we may start doning a “Properties Maintenance System” also I Draft-Down some points and brain-storming session [READ THE ARTICLE HERE]. In this Part -1 of the Properties Maintenance System
In this Post, we will see the Tables and the Fields, and will write the first Function to create the Data-Base and the tables, also Inserting the Zero-Records and the (some) Data in-to lookup tables. Also I will try to list-down all the Functions we may write in our Application. All the codes will be available in the Download Page.
Tables and Fields
- Name: Job Status Table (job_s_t). Type: Lookup.
- Name: Payment Method Table (pay_meth_t). Type: Lookup.
- Name: Property Type Table (prop_type_t). Type: Lookup.
- Name: Maintenance Job List Table (main_job_list_t). Type: Lookup.
- Name: Properties Table (properties_t).
- Name: Maintenance Request Table (maint_request_t)
- Name: Receipt Table (receipt_t)
[Any other Table we may add more tables if we need latre]
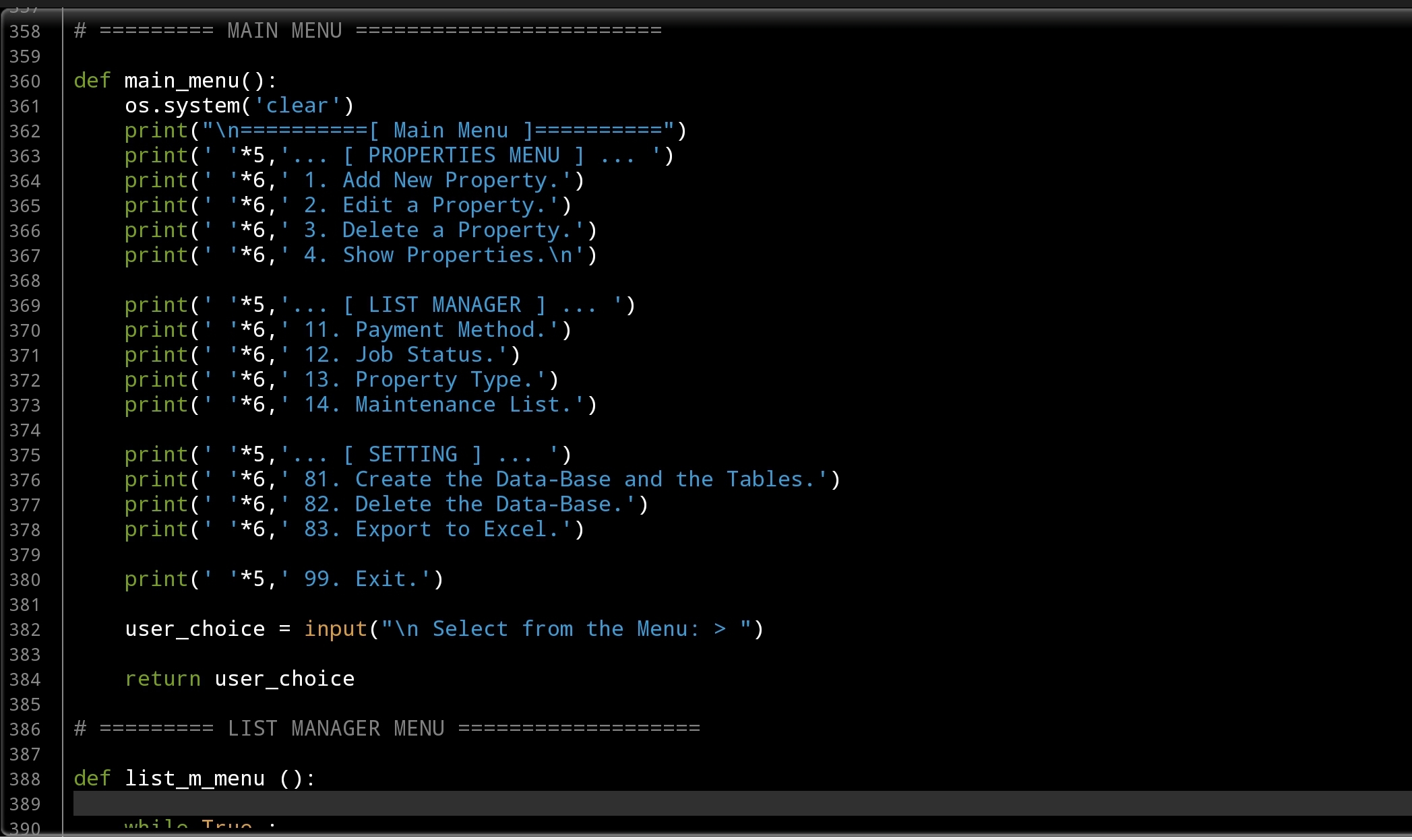
Function: Here i am listing all the Functions we will create, this list will be the Main Menu.
… [ PROPERTIES MENU ] …
- Add New Property.
- Edit a Property.
- Delete a Property.
- Show Properties.
… [ LIST MANAGER ] …
- Payment Method. [Add, Edit, Delete]
- Job Status. [Add, Edit, Delete]
- Property Type. [Add, Edit, Delete]
- Maintenance List. [Add, Edit, Delete]
- … [ SETTING ] …
- Create the Data-Base and the Tables.
- Delete the Data-Base.
- Export to Excel.
Function Exalmple: For each Function we have, this will be the template of the Function Name and the first three lines
# Sample of: Add Job Status Function
def add_job_status():
os.system('clear')
line2 = "Add Job Status"
header(line2, 9,14) # Calling the header Function.
Table Creation and Zero-Records I am always start writing the ideas in the Python Editor as comments, and coding in the same time, so by the time i collect all this article the Part-1 of the project was done with Tow or Three Functions that Creating the Tables and Inserting the data into lookup-Tables. Here I am posting some screen shots of the code..
 |
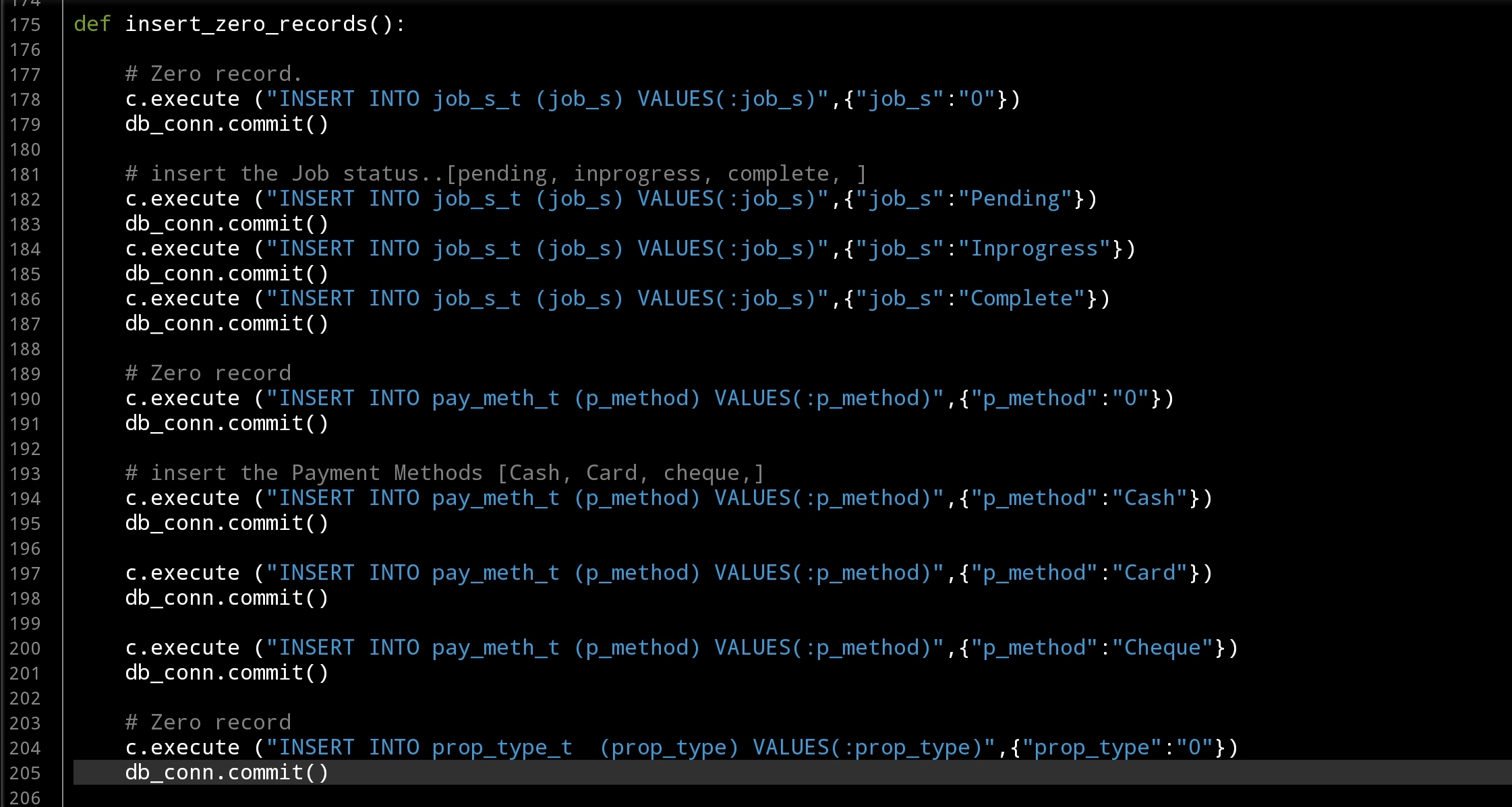 |
 |
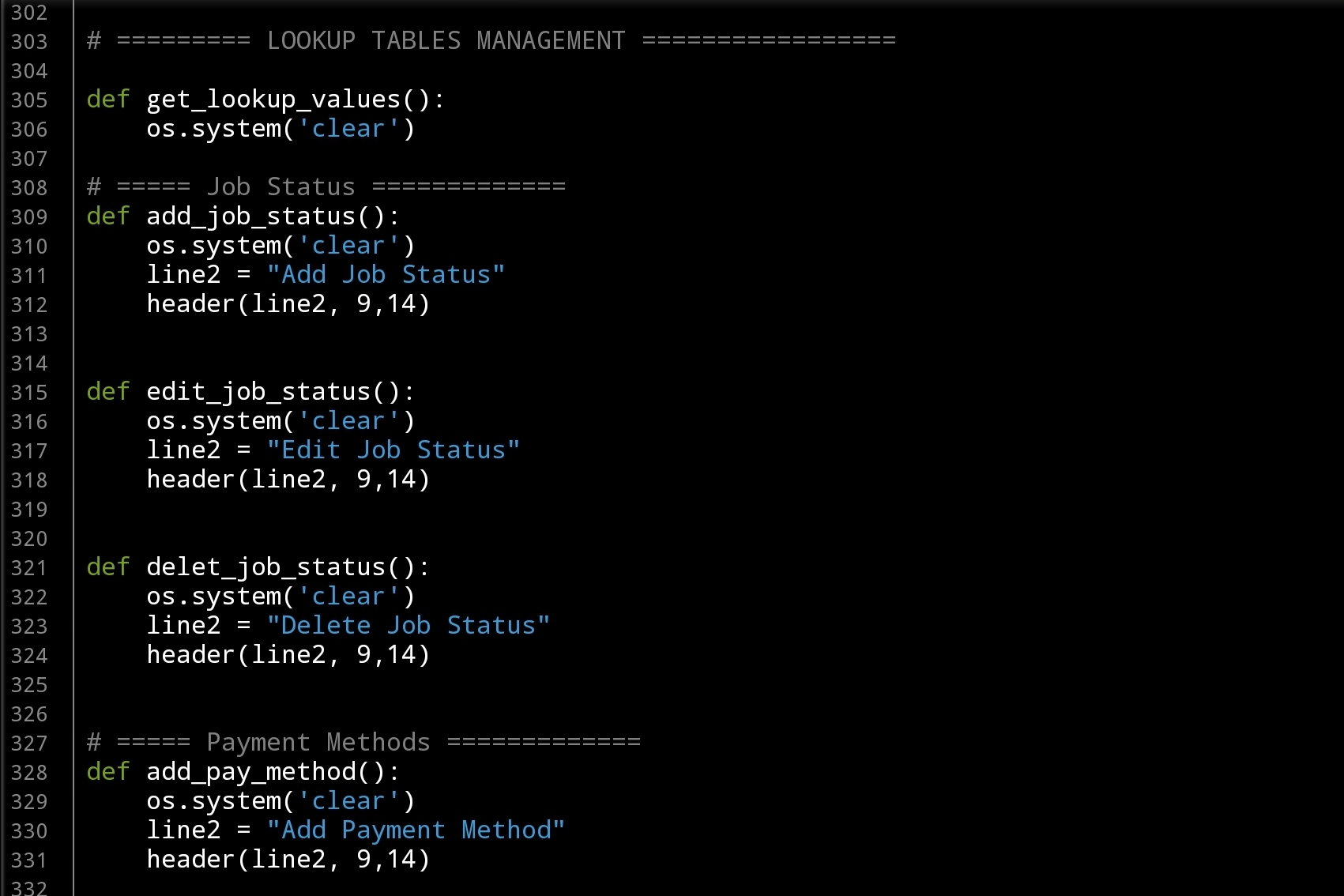 |
In Part-2 In Part-1 [This Article] We create the Data-Base and Tables, also Insert some Data into the lookup-tables and we create the Main-Menu Function. In Part-2 we will start writing some Functions to manage the lookup tables.
:: PMS Parts ::
| Part 1 | Part 2 | Part 3 | Part 4 |
..:: Have Fun with Coding ::.. 🙂
To Download my Python code (.py) files Click-Here
By: Ali Radwani
Python: Coffee Consumption P10
Learning : Python, SQlite3, Dataset, Pandas,
Subject: Create Coffee Consumption Application.
[NOTE: To keep the code as simple as we can, We WILL NOT ADD any user input Varevecations. Assuming that our user will Enter the right inputs.]
[ IF THE IS FIRST TIME DOWNLOADING THE CODE FILE, SELECT OPTION 7 FROM MAIN-MENU TO CREATE THE DATABASE]
In this Last part (Part-10) of Coffee Consumption App, we will write a Function to Export the Data to an Excel Fiel, So this will be the Last part of this application and any other Enhancement will be added as new version of the application.
Exporting The Data: To Export the data to or say “writing into” Excel file we need to import New library Named: xlsxwriter [if you don’t have the library then you need to install it first, using this command: pip install xlsxwriter]. After installing we will call it into our python file using this command: import xlsxwriter. The Excel file [in this case] will have four Sheets, named as follow:
coffee_con, coffee_name, coffee_type, coffee_size
each sheet will contains the table header and the date.
File Name: The file name will be as: coffee_consumption_[Current Date & Time].xlsx, the date and time will be formated as: yyyymmdd_HM, the python code to generate this is:
now = datetime.now()
date_t = now.strftime(“%Y%m%d_%H%M”)
Also we need to know that the file will be saved in the same directory of the application or (python .py file)
New Function: from our back_up function we will call another Function called: write_data(data_set,col_list,the_sheet): this Function will write the data-set into Excel file sheet, so we need to pass the data_set, column list and the Sheet Name as arguments to the function and it will use the command: write(row,col,data) to write the row to the sheet. Here is the code
# Writing the data into the sheet
def write_data(data_set,col_list,the_sheet):
"""
Function to write the data-set into Excel file sheet.
Argument:
data_set:
col_list: List of the columns in the data_set.
the_sheet: the Sheet Name.
"""
# write the Table Header
for x in range (0,len(col_list)):
the_sheet.write(0,x,col_list[x])
rows = len(data_set)
for row in range (1,rows) :
for col in range (0,len(col_list)) :
the_sheet.write(row,col,data_set[row][col])
In our main back-up function, we prepare the data-set and column list, then we call the new Function write_data passing the variable. Here is two parts of the code, first one is generating the file name, and calling the datetime function, second part is dealing with the data tables in the database, fetching the data, listing the columns and passing this to write_data function.. Here is the code
 |
 |
… Done. We finish the Coffee Consumption Application using Python and Sqlite. Next Week we will start New Application ..
..:: Have Fun with Coding ::.. 🙂
| Part 1 | Part 2 | Part 3 | Part 4 | Part 5 |
| Part 6 | Part 7 | Part 8 | Part 9 | Part 10 |
To Download my Python code (.py) files Click-Here
By: Ali Radwani
Python: Property Mainenance System
Project Name: Property Mainenance System
By: Ali Radwani
First-Draf: 5.10.2021 [Brin Storming]
I start writing the outline for a New Project about Renting System, one of the Functions in the system was Property Maintenance Service, then I notes that this Function can be a Stand-Alone System because of it’s Size and Requerment, so i decide to transfer the Property Maintenance Service into an Application.
Here are some Brain-Storming ideas [Not sorted, Not checked, Need to been Reviewed]
- Submit Maintenance Request (by Tenant) : (For What?: [Bathroom, kitchen, WaterSystem[Colling, Heating], Windoews and Doors, Paints, TV & Aoudio,Insects and Bugs, Roof, Others (If other please write.. )]
- Request Date,time
- Property address.
- Maintenance Suggested Date (by Tenant) [Need Maintenance team appoval]
- Cost Evaluation. [Tenant Approval Requear]
- IF Approved. Do Payment,[Cash, cheque, card] Set the Date and Time for the Maintenance.
- Start the job after payment.()
- After Maintenance Finsh Close the case.
- Print Report if requered.
- —> Tables:
- Properties: ID, Address[Zone, Street, Building],Type[Villa, Appartment], Bedroom(numbers), Bathroom(numbers), Kitchen(numbers),Car_garage(numbers), Intercome, TV_Cable, Internet, contract_period
- Maintenance_request: property ID, maintenance for, date_time status[pending, inprogress, complete],
- Payments: Total Cost, Date, Payed_by, Payment Method[cash,cheuq], Property ID, receipt id.
- completed: data, property ID, maintenance for, cost,
- —> look-up tables:
- job status: [pending, inprogress, complete, ]
- payment methods: [Cash, Card, cheque,]
- Maintenance List: [Bathroom, kitchen, WaterSystem[Colling, Heating], Windoews and Doors, Paints, TV & Aoudio, Insects and Bugs, Roof, Others (If other please write.. )]
- Functions:
- Main Menu.
- Add, Edit, Delete [For each Section/Function in the tables/Application]
- Show Data/Records.
- Reports
- submin_request.
… More to be added .. Needs:[Tables Name, ] .. Tables or functions may Merged or Deleted.
Python: Coffee Consumption P9
Learning : Python, SQlite3, Dataset, Pandas,
Subject: Create Coffee Consumption Application.
[NOTE: To keep the code as simple as we can, We WILL NOT ADD any user input Varevecations. Assuming that our user will Enter the right inputs.]
[ IF THE IS FIRST TIME DOWNLOADING THE CODE FILE, SELECT OPTION 7 FROM MAIN-MENU TO CREATE THE DATABASE]
In this part (Part-9) of Coffee Consumption App, we will write a Function to Edit a Record in the Main Table of the Coffee Consumption System. Because we are using Lookup tables for some of the data [Coffee Name, Type and Size] editing code may be longer that we will use the SQL Select commands several time to retrieve the data from those Tables. So first we will look to the steps we need to do (will do) in the Function:
1. Calling the show_records(inside = ‘yes’) function to display all the records on the screen.
2. In while True loop we will ask the user to Select the Record ID that want to Edit. We will do a Validation if the user select a valid ID using check_availabilty(‘coffee_con’,’c_id’, int(edit_rec_id)) != None)
3. Using SQL Command, We will Select the main record for Coffee_con Table, then again we will use the SQL to do the following:
— > SQL Command to get the Coffee Name for coffee_name Table using foreign key in coffee name cell.
— > SQL Command to get the Coffee Type for coffee_type Table using foreign key coffee type cell.
— > SQL Command to get the Coffee Size for coffee_size Table using foreign key coffee size cell.
Then we will display the Record and ask the use to confirm that this is the record to be edit.
4. After the user confirmation of Editing the Record, we will run three blocks of while True loop code for Coffee Name, Coffee Type and Coffee Size in each one we will display the data in the lookup Table, ask the user to Select ID from the List, if the user press on enter without writing any number then we will keep the current data, also we will do a validation on user input. Also will ask the user for Gender and Rank.
5. Now we have all the New Edited Date, we will display it on the screen asking the user [again] to confirm the “Saving The Changed” by Pressing the [S] (any thing else will be as “NO Don’t Save”).
Coding Now let’s see some parts of the code we use, the Source File of extention .py is available in the Download Page.
Here the user Selecting the ID of the Record to be Edit.
 |
The while True loop to edit the coffee Type.
 |
Last code part is to display the new edited record on the screen and the SQL command to UPDATE the DataBase.
 |
What’s Coming: In Part-10 we will write the Function to backup the data as Excel file.
..:: Have Fun with Coding ::.. 🙂
| Part 1 | Part 2 | Part 3 | Part 4 | Part 5 |
| Part 6 | Part 7 | Part 8 | Part 9 | Part – |
To Download my Python code (.py) files Click-Here
By: Ali Radwani
Python: Coffee Consumption P8
Learning : Python, SQlite3, Dataset, Pandas,
Subject: Create Coffee Consumption Application.
[NOTE: To keep the code as simple as we can, We WILL NOT ADD any user input Varevecations. Assuming that our user will Enter the right inputs.]
[ IF THE IS FIRST TIME DOWNLOADING THE CODE FILE, SELECT OPTION 7 FROM MAIN-MENU TO CREATE THE DATABASE]
In this part (Part-8) of Coffee Consumption App, we will write a Function to Delete a Record from the Main Table of the Coffee Consumption System.
Deleting a record is an easy SQL command having the Table Name and the Record ID that we want to Delete. In our Function First we wil display all the Records on the screen and asking the user to Select the ID of the Record, then we will display that record (again) on the screen and ask to Confirm the action by Entering [Y].
If the user Enter [Y] the Record will be Deleted, any thing else it wil be as No and the user will returned to the Main-Menu.
Coding: We will start the Function by displaying the header, then we will call the Function that will display all the Records in the data-base.. Here is the code..
show_records(inside = ‘yes’)
and asking the user to Select the ID.
NEXT: We will check the Availability of the ID, so if the user Enter an ID that not in the Data-Base or Empty space or just press Enter we will ask to re-enter the ID again. … Here is the code ..
while True:
del_rec_id = input (‘\n\n Select the Record ID to be Deleted > ‘)
if del_rec_id in [‘e’,’E’]:
input(‘ You Select [E to Exit].. Press any Key. > ‘)
return
elif (del_rec_id ==” “) or (del_rec_id ==””) or (check_availabilty(‘coffee_con’,’c_id’, int(del_rec_id)) != None):
break
If the ID is available, then we will display the Record and will ask the user to Confirm the Delete Command. This is the code for all the Delete Function ..
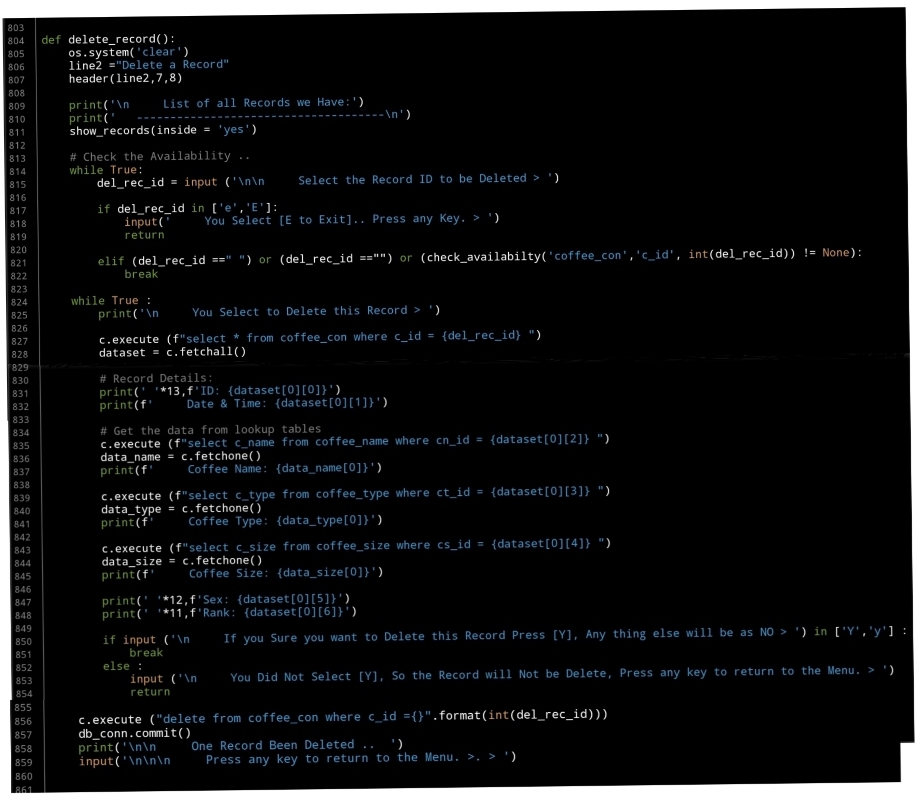 |
What’s Coming: In Part-9 we will Writing the Function to Edit a Coffee Record.
..:: Have Fun with Coding ::.. 🙂
| Part 1 | Part 2 | Part 3 | Part 4 | Part 5 |
| Part 6 | Part 7 | Part 8 | Part – | Part – |
To Download my Python code (.py) files Click-Here
By: Ali Radwani
Taking pictures is not my main daily practices, but when i start playing with my camera, i really enjoy my self.
Thanks for visiting my Space..



